

A Study on Estimating OD Trips From Observed Link Flows——Based on the Method of Iterative Procedure to Calculate OD on the Multi-path Assignment Model
Article Text (Baidu Translation)
-
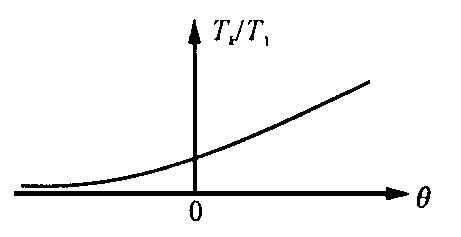
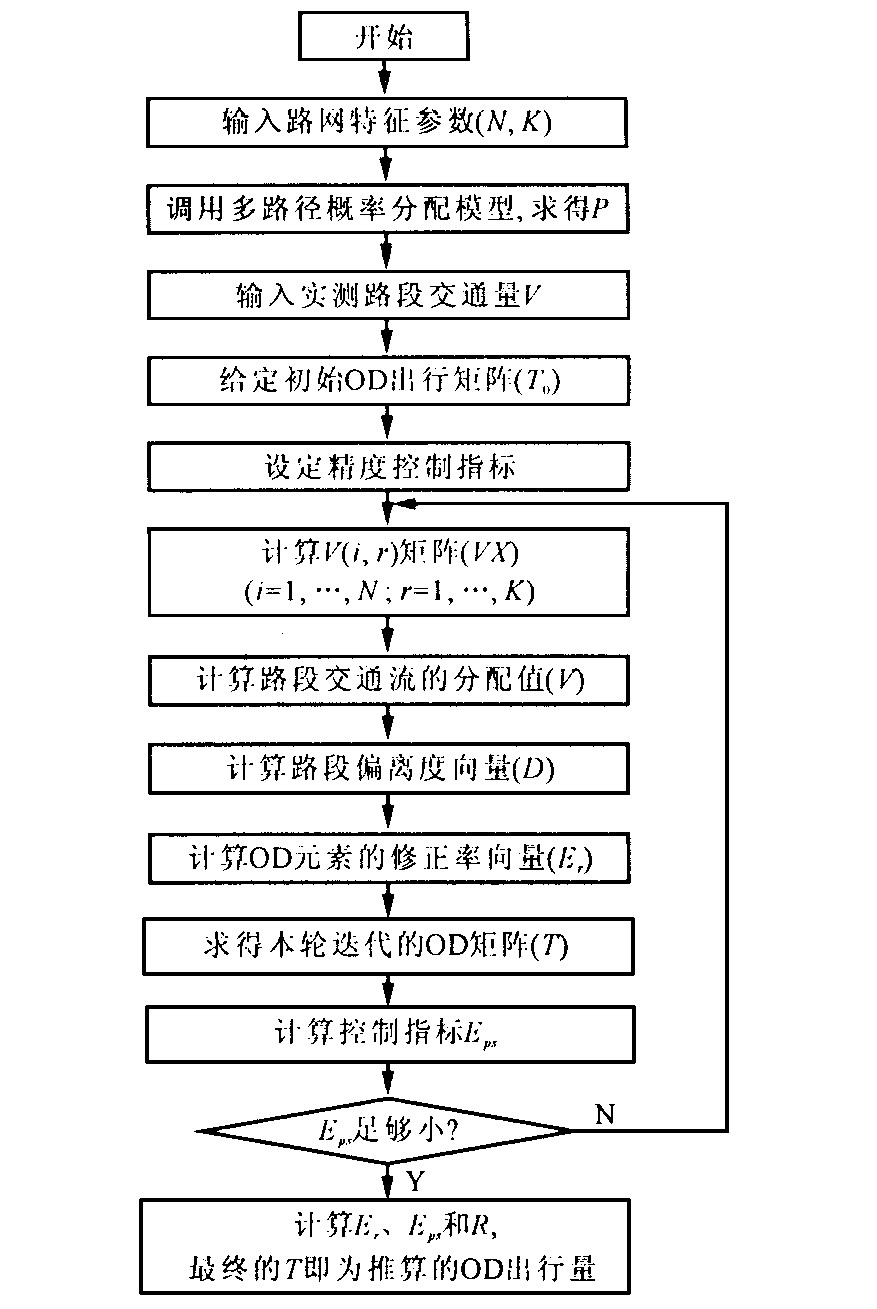
摘要: 在改进有效路段和有效路径定义的基础上, 采用随机—最短路多路径分配模型, 求解分配率矩阵, 建立了多路径分配模型的迭代反推方法, 并采用假设论证法检验了方法系统的可靠性、合理性。讨论了影响出行量推算结果的主要因素, 获得了因变于分配率矩阵的两个重要结论Abstract: A new iteration framework of estimating OD trips is established by a stochastic shortest path multi path assignment model to calculate the probability matrix P based on the two improved definitions of effective path and effective link.Meanwhile a hypothesis argumentation is put forward to examine the feasibility and rationality of the iteration method.Then the factors of influencing result of estimation are discussed.Finally two important conclusions resulted from P are obtained.
-
[1] 王炜, 等. 城市交通规划理论及其应用[M]. 南京: 东南大学出版社, 1998. [2] 李景. 由路段交通量推算OD出行量的实用方法研究[D]. 长沙: 长沙交通学院, 1999. -
 下载:
下载:
 点击查看大图
点击查看大图
图(2)
计量
- 文章访问数: 509
- HTML全文浏览量: 109
- PDF下载量: 482
- 被引次数: 0
