

-
摘要: 采用连续图像帧作为输入,挖掘连续图像帧之间的时序关联信息,构建一种融合时序信息的多任务联合驾驶环境视觉感知算法,通过多任务监督联合优化,实现交通参与目标的快速检测,同时获取可通行区域信息;采用ResNet50作为骨干网络,在骨干网络中构建级联特征融合模块,捕捉不同图像帧之间的非局部远程依赖关系,将高分辨率图像通过卷积下采样处理,加速不同图像帧的特征提取过程,平衡算法的精度和速度;在不同的图像帧中,为了消除由于物体运动产生的空间位移对特征融合的影响,且考虑不同图像帧的非局部关联信息,构建时序特征融合模块分别对不同图像帧对应的特征图进行时序对齐与匹配,形成融合全局特征;基于共享参数的骨干网络,利用生成关键点热图的方法对道路中的行人、车辆和交通信号灯的位置进行检测,并利用语义分割子网络为自动驾驶汽车提供道路可行驶区域信息。研究结果表明:提出的感知算法以多帧图像代替单一帧图像作为输入,利用了多帧图像的序列特性,级联特征融合模块通过下采样使得计算复杂度降低为原来的1/16,与CornerNet、ICNet等其他主流模型相比,算法检测精确率平均提升了6%,分割性能平均提升了5%,并保持了每秒12帧图像的处理速度,在检测与分割速度和精度上具有明显优势。Abstract: The sequential image frames were used as input to mine the temporal associated information among the continuous image frames, and a multi-task joint driving environment perception algorithm fusing the temporal information was constructed to rapidly detect the traffic participation targets and drivable area through multi-task supervision and joint optimization. ResNet50 was used as the backbone network, in which a cascaded feature fusion module was built to capture the non-local remote dependence among different image frames. The high-resolution images were processed by the convolution subsampling to accelerate the feature extraction process of different image frames, balancing the detection accuracy and speed of the algorithm. In order to eliminate the influence of spatial displacements of the objects among the image frames on the feature fusion, and considering the non-local dependence of the features of different image frames, the temporal feature fusion module was constructed to align and match the time sequences of feature maps corresponding to different image frames for forming the integrated global feature. Based on the parameter-sharing backbone network, the heat map of generating key point was exploited to detect the positions of pedestrians, vehicles and traffic signal lights on the road, and the semantic segmentation sub-network was built to provide the drivable area information for autonomous vehicles on the road. Analysis results show that the proposed algorithm takes sequential frames as input instead of single frame, which makes effective use of the temporal characteristics of the frames. In addition, its computational complexity with the cascaded feature fusion module greatly reduces to sixteenth of that without the cascaded feature fusion module through downsampling. Compared with other mainstream models, such as CornerNet and ICNet, the detection accuracy and segmentation performance of the algorithm improve by an average of 6% and 5%, respectively, and the image processing speed reaches to 12 frames per second. Therefore, the proposed algorithm has obvious advantages in the speed and accuracy of image detection and segmentation. 6 tabs, 9 figs, 31 refs.
-
表 1 目标检测子任务试验结果
Table 1. Experimental results of object detection subtask
算法 骨干网络 速度/(帧·s-1) 平均精确率/% 召回率/% YOLOv3[11] Darknet53 24.0 79.2 84.9 Mask R-CNN[29] ResNeXt-101 11.4 84.2 86.2 CornerNet[12] Hourglass-104 4.6 86.9 86.5 CenterNet[13] ResNet101 6.8 87.6 87.2 TridentNet[30] ResNeXt-101-DCN 0.7 91.0 88.3 MadNet(Ours) ResNet50 12.6 89.8 87.8 MadNet(Ours) ResNet101-DCN 5.9 91.8 90.1  下载: 导出CSV
下载: 导出CSV
表 3 多任务联合试验结果
Table 3. Multi-task joint experiment results
骨干网络 速度/(帧·s-1) 平均交并比/% 平均精确率/% 召回率/% ResNet50 11.5 79.3 90.2 88.4 ResNet101-DCN 5.1 81.6 92.4 90.5
下载: 导出CSV
表 4 级联特征融合模块不同插入位置的试验结果
Table 4. Experimental results of cascade feature fusion module at different insertion positions
插入位置 速度/(帧·s-1) 平均交并比/% 平均精确率/% 召回率/% Stage1之后 14.0 74.8 85.7 83.4 Stage2之后 12.8 77.3 88.4 85.7 Stage3之后 11.5 79.3 90.2 88.4 Stage4之后 8.4 79.6 90.5 87.6
下载: 导出CSV
表 5 具体对象的检测精确率
Table 5. Detection precisions of specific objects
平均精确率/% 具体对象的检测精确率/% 自行车 卡车 行人 汽车 交通信号灯 92.4 88.5 94.4 96.2 97.7 90.2
下载: 导出CSV
表 6 不同数量图像帧输入对算法性能的影响
Table 6. Influence of different numbers of input image frames on algorithm performance
输入图像帧数 速度/(帧·s-1) 平均交并比/% 平均精确率/% 召回率/% 2 11.5 79.3 90.2 88.4 3 8.6 79.7 91.2 88.4 4 4.4 79.8 91.2 88.6
下载: 导出CSV
-
[1] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[C]//ICLR. 3rd International Conference on Learning Representations. San Diego: ICLR, 2015: 357-361. [2] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. doi: 10.1109/TPAMI.2017.2699184 [3] CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. https://arxiv.org/abs/1706.05587, 2017-08-08/2017-12-05. [4] CHEN L C, ZHU Yu-kun, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Springer. 15th European Conference on Computer Vision. Berlin: Springer, 2018: 833-851. [5] ZHAO Heng-shuang, SHI Jian-ping, QI Xiao-juan, et al. Pyramid scene parsing network[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 6230-6239. [6] ZHAO Heng-shuang, QI Xiao-juan, SHEN Xiao-yong, et al. ICNet for real-time semantic segmentation on high-resolution images[C]//Springer. 15th European Conference on Computer Vision. Berlin: Springer, 2018: 418-434. [7] LIU Zhan-wen, QI Ming-yuan, SHEN Chao, et al. Cascade saccade machine learning network with hierarchical classes for traffic sign detection[J]. Sustainable Cities and Society, 2021, 67: 30914-30928. http://www.sciencedirect.com/science/article/pii/S2210670720309148 [8] REN Shao-qing, HE Kai-ming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. doi: 10.1109/TPAMI.2016.2577031 [9] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 779-788. [10] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 6517-6525. [11] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. https://arxiv.org/abs/1804.02767, 2018-04-08. [12] LAW H, DENG Jia. CornerNet: detecting objects as paired keypoints[J]. International Journal of Computer Vision, 2020, 128(3): 642-656. doi: 10.1007/s11263-019-01204-1 [13] ZHOU Xing-yi, WANG De-quan, KRÄHENBVHL P. Objects as points[EB/OL]. https://arxiv.org/abs/1904.07850v1, 2019-04-16/2019-04-25. [14] ZHAO Yi, QI Ming-yuan, LI Xiao-hui, et al. P-LPN: towards real time pedestrian location perception in complex driving scenes[J]. IEEE Access, 2020, 8: 54730-54740. doi: 10.1109/ACCESS.2020.2981821 [15] TEICHMANN M, WEBER M, ZÖLLNER M, et al. MultiNet: Real-time joint semantic reasoning for autonomous driving[C]//IEEE. 2018 IEEE Intelligent Vehicles Symposium. New York: IEEE, 2018: 1013-1020. [16] SISTU G, LEANG I, YOGAMANI S. Real-time joint object detection and semantic segmentation network for automated driving[EB/OL]. https://arxiv.org/abs/1901.03912, 2019-06-12. [17] CHEN Zhao, BADRINARAYANAN V, LEE C Y, et al. GradNorm: gradient normalization for adaptive loss balancing in deep multitask networks[C]//ICML. 35th International Conference on Machine Learning. Stockholm: ICML, 2018: 794-803. [18] KENDALL A, GAL Y, CIPOLLA R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics[C]//IEEE. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 7482-7491. [19] SENER O, KOLTUN V. Multi-task learning as multi-objective optimization[C]//IFIP. 32nd International Conference on Neural Information Processing Systems. Rome: IFIP, 2017: 525-526. [20] ZHAO Xiang-mo, QI Ming-yuan, LIU Zhan-wen, et al. End-to-end autonomous driving decision model joined by attention mechanism and spatiotemporal features[J]. IET Intelligent Transport Systems, 2021, 8: 1119-1130. http://www.researchgate.net/publication/352733796_End-to-end_autonomous_driving_decision_model_joined_by_attention_mechanism_and_spatiotemporal_features [21] LI Yu-le, SHI Jian-ping, LIN Da-hua. Low-latency video semantic segmentation[C]//IEEE. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 5997-6005. [22] FENG Jun-yi, LI Song-yuan, LI Xi, et al. TapLab: a fast framework for semantic video segmentation tapping into compressed-domain knowledge[J]. IEEE Transactions on Software Engineering, 2020, https://ieeexplore.ieee.org/document/9207876. [23] WU Jun-rong, WEN Zong-zheng, ZHAO San-yuan, et al. Video semantic segmentation via feature propagation with holistic attention[J]. Pattern Recognition, 2020, 104, DOI: 10.1016/j.patcog.2020.107268. [24] HE Kai-ming, ZHANG Xiang-yu, REN Shao-qing, et al. Identity mappings in deep residual networks[C]//ACM. 14th European Conference on 21st ACM Conference on Computer Vision. Berlin: Springer, 2016: 630-645. [25] HU Ping, HEILBRON F C, WANG O, et al. Temporally distributed networks for fast video semantic segmentation[C]//IEEE. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 8815-8824. [26] ZHU Zhen, XU Meng-du, BAI Song, et al. Asymmetric non-local neural networks for semantic segmentation[C]//IEEE. 2019 International Conference on Computer Vision. New York: IEEE, 2019: 593-602. [27] CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 3213-3223. [28] YUN S D, HAN D Y, OH S J, et al. CutMix: regularization strategy to train strong classifiers with localizable features[C]//IEEE. 2019 International Conference on Computer Vision. New York: IEEE, 2019: 6022-6031. [29] HE Kai-ming, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 386-397. doi: 10.1109/TPAMI.2018.2844175 [30] LI Yang-hao, CHEN Yun-tao, WANG Nai-yan, et al. Scale-aware trident networks for object detection[C]//IEEE. 2019 International Conference on Computer Vision. New York: IEEE, 2019: 6053-6062. [31] ZHU Xi-zhou, XIONG Yu-wen, DAI Ji-feng, et al. Deep feature flow for video recognition[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 4141-4150. -
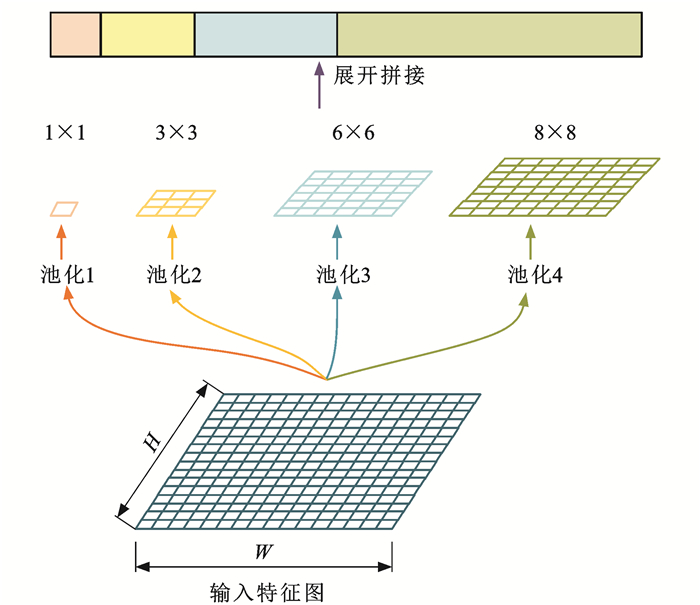

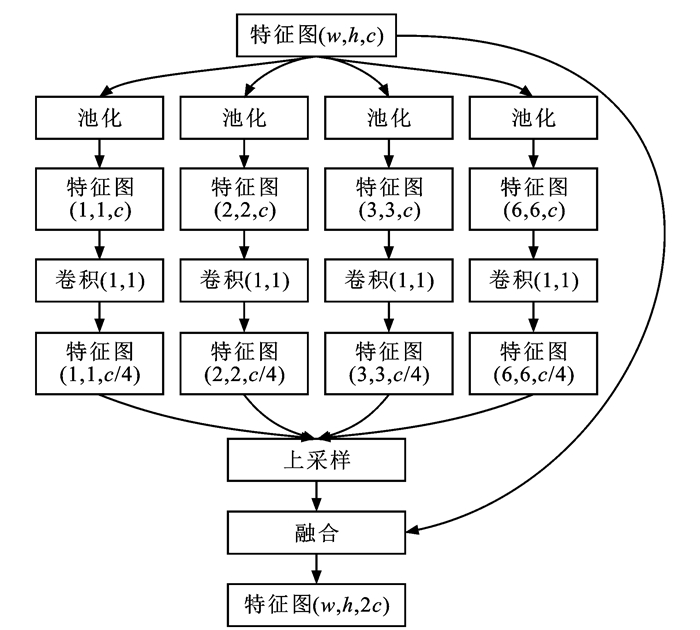



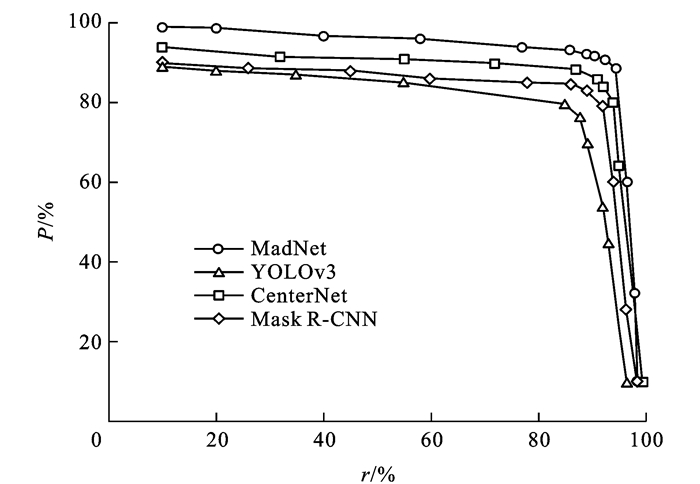

 点击查看大图
点击查看大图

计量
- 文章访问数: 1144
- HTML全文浏览量: 274
- PDF下载量: 131
- 被引次数: 0
