

Traffic sign detection algorithm based on pyramid multi-scale fusion
-
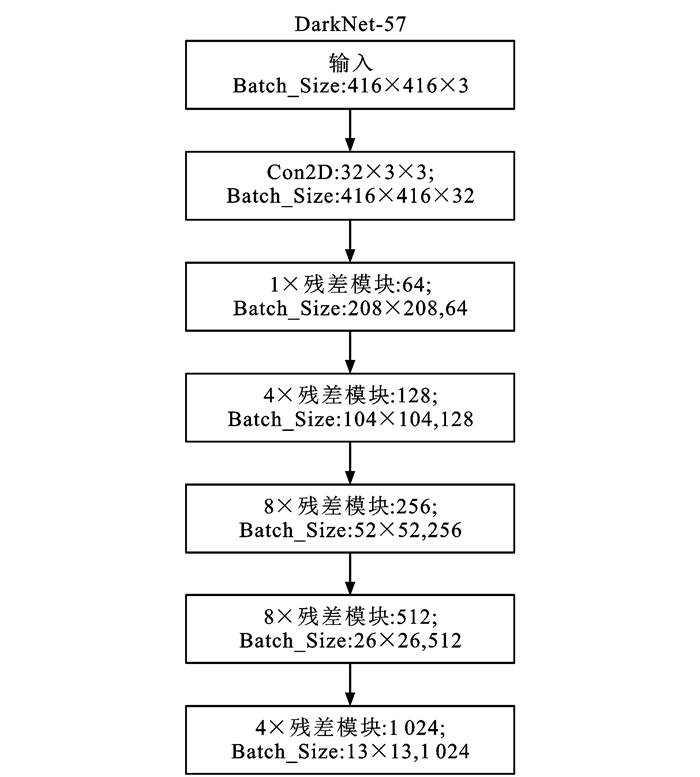
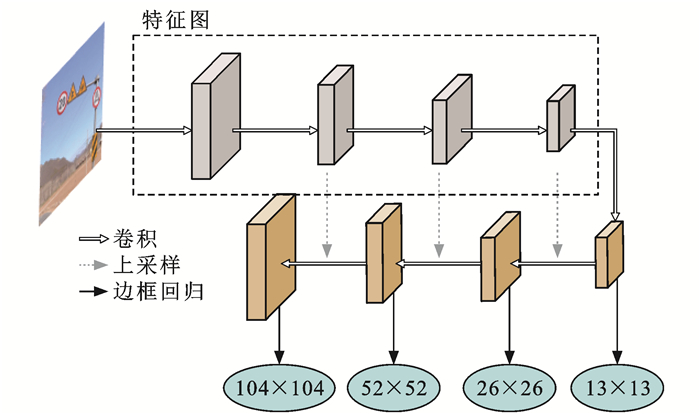
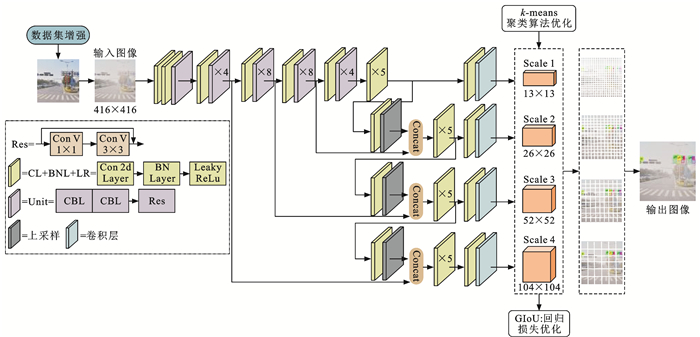
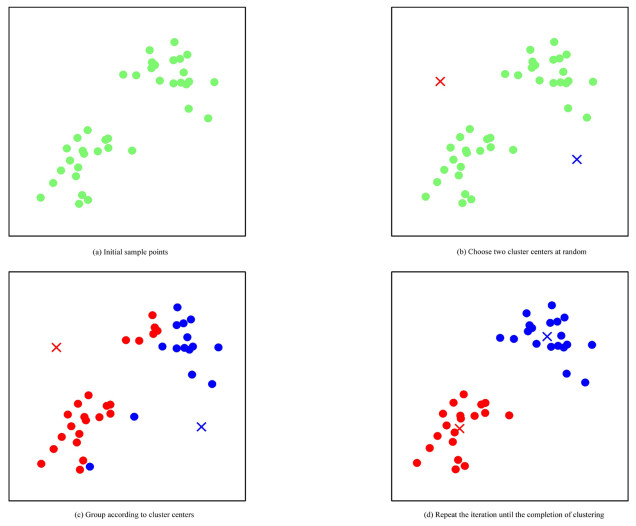
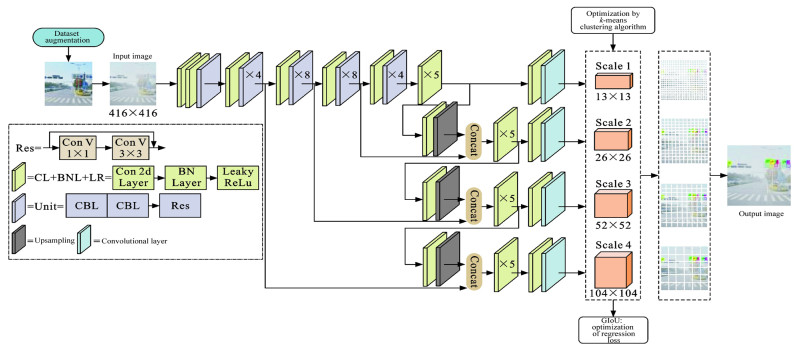
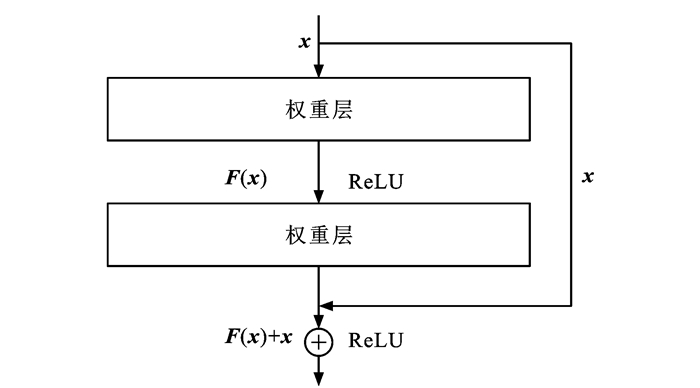
摘要: 为了解决传统交通标志检测算法针对小目标交通标志检测时存在误检与漏检的问题,提出了一个基于金字塔多尺度融合的交通标志检测算法;为了提高算法对交通标志的特征提取能力,引入ResNet残差结构搭建算法的主干网络,并增加网络浅层卷积层数,以提取较小尺度交通标志目标更准确的语义信息;基于特征金字塔结构的思想,在检测结构中引入4个不同预测尺度,增强深层和浅层特征融合;为了进一步提高算法检测精度,引入GIoU损失函数定位交通标志的锚点框,利用k-means算法对交通标志标签信息进行聚类分析并生成更精准的先验框;为了验证算法的泛化性与解决试验所用数据集TT100K的类间不平衡问题,增强与扩充了数据集。试验结果表明:本文算法的精确率、召回率与平均精度均值分别达到了86.7%、89.4%与87.9%,与传统目标检测算法相比有显著提高;多尺度融合检测机制、GIoU损失函数与k-means的引入能够不同程度提高算法的检测性能,使算法检测精确率分别提升4.7%、1.8%与1.2%;提出算法针对不同尺度交通标志检测时均有更优越的性能表现,在TT100K数据集中的(0, 32]、(32, 96]与(96, 400]尺度下的检测召回率分别达到90%、93%与88%;与YOLOv3相比,提出算法在不同天气、噪声与几何变换等干扰下均能实现对交通标志的正确定位与分类,证明了提出算法具有良好的鲁棒性与泛化性,适用于道路交通标志检测。Abstract: In order to address the problems of misdetection and missing detection for small target traffic signs in traditional traffic sign detection algorithms, a traffic sign detection algorithm based on pyramidal multi-scale fusion was proposed. To improve the feature extraction capability of the algorithm for traffic signs, the residual structure of ResNet was adopted to build the backbone network of the algorithm, and, the number of shallow convolutional layers of the backbone network was increased to extract more accurate semantic information of smaller scale traffic signs. Based on the idea of feature pyramid network, four different prediction scales were introduced in the detection network to enhance the fusion between deep and shallow features. To further improve the detection accuracy of the algorithm, the GIoU loss function was introduced to localize the anchor boxes of traffic signs. Meanwhile, the k-means algorithm was introduced to cluster the traffic sign label information and generate more accurate prior bounding boxes. In order to verify the generalization of the algorithm and solve the problem of inter-class imbalance of TT100K data set used in the experiment, the data set was enhanced and expanded. Experimental results show that the accuracy, recall and average accuracy of the proposed algorithm are 86.7%, 89.4% and 87.9%, respectively, significantly improving compared with traditional target detection algorithms. The adoption of multi-scale fusion detection mechanism, GIoU loss function and k-means improves the detection performance of the algorithm to different degrees, and its precision improves by 4.7%, 1.8% and 1.2%, respectively. The algorithm has better performance in the detection of traffic signs under different scales, and its recall rate is 90%, 93% and 88% under the scales of (0, 32], (32, 96] and (96, 400] in TT100K dataset, respectively. Comparing with YOLOv3, the proposed algorithm can correctly locate and classify traffic signs under the interference of different weather, noise and geometric transformation, which proves that the proposed algorithm has good robustness and generalization, and is suitable for road traffic sign detection. 7 tabs, 18 figs, 30 refs.
-

图 6 预测框与真实框无重叠情况下IoU的表达
Figure 6. Expression of prior bounding box and anchor box without overlap under IoU

图 7 预测框与真实框无重叠情况下GIoU的表达
Figure 7. Expression of prior bounding box and anchor box without overlap under GIoU

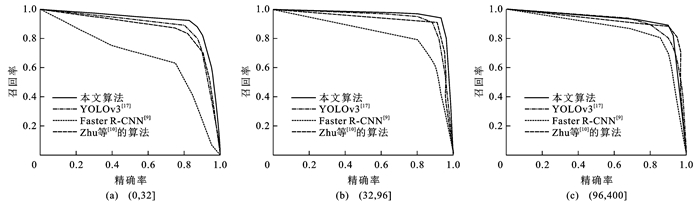
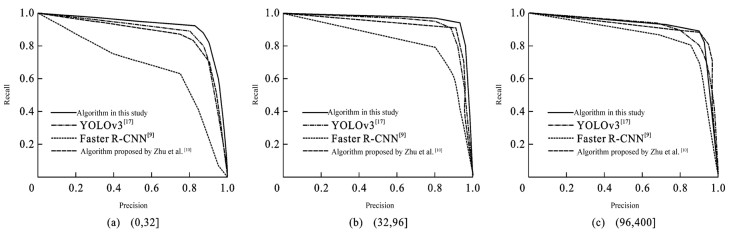
图 12 四种算法在TT100K三种尺度下的P-R曲线对比
Figure 12. P-R curves comparison of four algorithms tested under three scales on TT100K

图 13 FPN-TSD与YOLOv3在原始数据集下检测结果对比
Figure 13. Comparison of detection results of FPN-TSD and YOLOv3 on original dataset

图 14 FPN-TSD与YOLOv3在雾天条件下检测结果对比
Figure 14. Comparison of detection results of FPN-TSD and YOLOv3 under foggy weather condition

图 15 FPN-TSD与YOLOv3在噪声条件下检测结果对比
Figure 15. Comparison of detection results of FPN-TSD and YOLOv3 under noisy condition

图 16 FPN-TSD与YOLOv3在雨天条件下检测结果对比
Figure 16. Comparison of detection results of FPN-TSD and YOLOv3 under rainy weather condition

图 17 FPN-TSD与YOLOv3在几何变换下的检测结果1对比
Figure 17. Comparison of detection results 1 of FPN-TSD and YOLOv3 under geometric transformation

图 18 FPN-TSD与YOLOv3在几何变换下的检测结果2对比
Figure 18. Comparison of detection results 2 of FPN-TSD and YOLOv3 under geometric transformation

14. Comparison of detection results of FPN-TSD and YOLOv3 under foggy weather condition

16. Comparison of detection results of FPN-TSD and YOLOv3 under rainy weather condition

17. Comparison of detection results 1 of FPN-TSD and YOLOv3 under geometric transformation

18. Comparison of detection results 2 of FPN-TSD and YOLOv3 under geometric transformation
表 1 各尺度特征图对应锚点框尺度
Table 1. Anchor box scales of each scale feature map
特征图尺度 先验框尺度 13×13 (3, 4)、(5, 5)、(5, 10) 26×26 (6, 7)、(8, 9)、(11, 12) 52×52 (12, 23)、(14, 15)、(19, 20) 104×104 (25, 27)、(36, 38)、(62, 64)  下载: 导出CSV
下载: 导出CSV
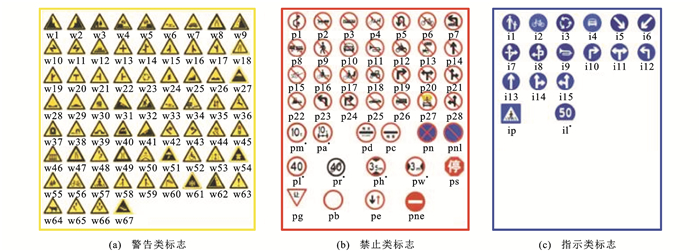
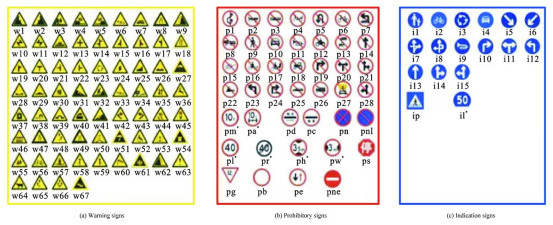
表 2 试验所用交通标志
Table 2. Traffic signs utilized in experiment
分类 标志 警告类 wo、w13、w32、w55、w57、w59 禁止类 pn、pne、pg、po、p3、p5、p6、p10、p11、p12、p19、p23、p26、p27、pr40、ph4、ph4.5、ph5、pm20、pm30、pm55 指示类 io、ip、i2、i4、i5、il60、il80、il100
下载: 导出CSV
表 4 三种尺度交通标志下四种算法检测结果
Table 4. Detection results of four algorithms under three scales of traffic signs
下载: 导出CSV
表 5 四种算法检测实时性对比
Table 5. Detection speed comparison of four algorithms
下载: 导出CSV
表 6 消融试验结果对比
Table 6. Comparison of ablation test results
算法 P/% R/% $ {\bar B}$ /% 1 81.1 84.3 83.6 2 85.8 86.1 86.7 3 82.9 84.6 84.8 4 82.3 85.8 84.3 5 86.7 89.4 87.9
下载: 导出CSV
表 7 算法准确率对比
Table 7. Accuracy comparison of algorithms
算法 i2 i4 i5 il100 il60 il80 io ip p10 p11 p12 p19 p23 p26 p27 Faster R-CNN[9] 0.44 0.46 0.45 0.41 0.57 0.62 0.41 0.39 0.45 0.38 0.60 0.59 0.65 0.50 0.79 YOLOv3[17] 0.85 0.92 0.93 0.96 0.89 0.89 0.85 0.88 0.83 0.88 0.82 0.83 0.89 0.89 0.90 Zhu等[10]的算法 0.72 0.83 0.92 1.00 0.91 0.93 0.76 0.87 0.78 0.89 0.88 0.53 0.87 0.82 0.78 Liang等[11]的算法 0.90 0.92 0.94 0.93 0.98 0.94 0.86 0.90 0.89 0.90 0.94 0.75 0.93 0.89 0.98 MSA_YOLOv3[22] 0.85 0.84 0.92 0.85 0.95 0.89 0.85 0.90 0.74 0.72 0.78 0.73 0.82 0.81 0.83 Wu等[24]的算法 0.41 0.62 0.93 0.89 0.79 0.93 0.81 0.81 0.75 0.80 0.90 0.86 0.84 0.85 0.74 本文算法 0.92 0.94 0.94 0.97 0.92 0.94 0.88 0.93 0.91 0.93 0.92 0.89 0.98 0.91 0.88 算法 pl120 p5 p6 pg ph4 ph4.5 ph5 pl100 p3 pl20 pl30 pl40 pl5 pl50 pl60 Faster R-CNN[9] 0.67 0.57 0.75 0.80 0.67 0.58 0.51 0.68 0.48 0.51 0.43 0.52 0.53 0.39 0.53 YOLOv3[17] 0.92 0.91 0.83 0.87 0.75 0.75 0.58 0.94 0.79 0.77 0.83 0.91 0.84 0.88 0.82 Zhu等[10]的算法 0.98 0.95 0.87 0.91 0.82 0.88 0.82 0.98 0.91 0.96 0.94 0.96 0.94 0.94 0.93 Liang等[11]的算法 0.96 0.91 0.90 0.93 0.94 0.80 0.78 0.98 0.81 0.90 0.92 0.91 0.92 0.90 0.95 MSA_YOLOv3[22] 0.80 0.77 0.72 0.92 0.82 0.83 0.63 0.88 0.81 0.75 0.74 0.74 0.78 0.72 0.76 Wu等[24]的算法 0.93 0.92 0.82 0.94 0.64 0.92 0.76 0.89 0.86 0.76 0.68 0.90 0.86 0.83 0.91 本文算法 0.98 0.96 0.95 0.93 0.87 0.90 0.87 0.95 0.93 0.93 0.96 0.97 0.94 0.96 0.97 算法 pl70 pl80 pm20 pne pm55 pn pm30 po pr40 w13 w32 w55 w57 w59 wo Faster R-CNN[9] 0.81 0.52 0.61 0.47 0.61 0.37 0.61 0.37 0.75 0.33 0.54 0.39 0.48 0.39 0.37 YOLOv3[17] 0.81 0.90 0.79 0.94 0.78 0.91 0.80 0.70 0.82 0.69 0.81 0.77 0.89 0.61 0.51 Zhu等[10]的算法 0.95 0.95 0.91 0.93 0.60 0.92 0.81 0.84 0.76 0.65 0.89 0.86 0.95 0.75 0.52 Liang等[11]的算法 0.98 0.92 0.98 0.97 0.86 0.90 0.97 0.81 0.79 0.90 0.91 0.89 0.90 0.68 0.50 MSA_YOLOv3[22] 0.79 0.72 0.76 0.96 0.71 0.83 0.67 0.76 0.85 0.70 0.91 0.79 0.85 0.73 0.53 Wu等[24]的算法 0.81 0.95 0.85 0.93 0.96 0.76 0.55 0.55 0.90 0.91 0.82 0.92 0.91 0.85 0.47 本文算法 0.94 0.97 0.93 0.98 0.83 0.94 0.98 0.89 0.91 0.72 0.93 0.93 0.91 0.89 0.55
下载: 导出CSV
1. Anchor box scales corresponding to feature maps of different scales

2. Traffic signs utilized in the experiment

3. Confusion matrix

4. Detection results of four algorithms at three scales of traffic signs

5. Detection speed comparison among four algorithms

6. Comparison of ablation experiment results

7. Accuracy comparison among algorithms

-
[1] 马永杰, 马芸婷, 程时升, 等. 基于改进YOLOv3模型与Deep-SORT算法的道路车辆检测方法[J]. 交通运输工程学报, 2021, 21(2): 222-231. https://www.cnki.com.cn/Article/CJFDTOTAL-JYGC202102022.htmMA Yong-jie, MA Yun-ting, CHENG Shi-sheng, et al. Road vehicle detection method based on improved YOLOv3 model and deep-SORT algorithm[J]. Journal of Traffic and Transportation Engineering, 2021, 21(2): 222-231. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-JYGC202102022.htm [2] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]//IEEE. 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2005: 886-893. [3] PICCIOLI G, DE MICHEL E, PARODI P, et al. Robust method for road sign detection and recognition[J]. Image and Vision Computing, 1996, 14(3): 209-223. doi: 10.1016/0262-8856(95)01057-2 [4] 梁敏健, 崔啸宇, 宋青松, 等. 基于HOG-Gabor特征融合与Softmax分类器的交通标志识别方法[J]. 交通运输工程学报, 2017, 17(3): 151-158. doi: 10.3969/j.issn.1671-1637.2017.03.016LIANG Min-jian, CUI Xiao-yu, SONG Qing-song, et al. Traffic sign recognition method based on HOG-Gabor feature fusion and Softmax classifier[J]. Journal of Traffic and Transportation Engineering, 2017, 17(3): 151-158. (in Chinese) doi: 10.3969/j.issn.1671-1637.2017.03.016 [5] DENG Li, ABDEL-HAMID O, YU Dong. A deep convolutional neural network using heterogeneous pooling for trading acoustic invariance with phonetic confusion[C]//IEEE. 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. New York: IEEE, 2013: 6669-6673. [6] 马永杰, 程时升, 马芸婷, 等. 卷积神经网络及其在智能交通系统中的应用综述[J]. 交通运输工程学报, 2021, 21(4): 48-71. https://www.cnki.com.cn/Article/CJFDTOTAL-JYGC202104006.htmMA Yong-jie, CHENG Shi-sheng, MA Yun-ting, et al. Review of convolutional neural network and its application in intelligent transportation system[J]. Journal of Traffic and Transportation Engineering, 2021, 21(4): 48-71. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-JYGC202104006.htm [7] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//IEEE. 27th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2014: 580-587. [8] GIRSHICK R. Fast R-CNN[C]//IEEE. 28th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2015: 1440-1448. [9] REN Shao-qing, HE Kai-ming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. doi: 10.1109/TPAMI.2016.2577031 [10] ZHU Zhe, LIANG Dun, ZHANG Song-hai, et al. Traffic- sign detection and classification in the wild[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 2110-2118. [11] LIANG Zhen-wen, SHAO Jie, ZHANG Dong-yang, et al. Traffic sign detection and recognition based on pyramidal convolutional networks[J]. Neural Computing and Applications, 2020, 32(11): 6533-6543. doi: 10.1007/s00521-019-04086-z [12] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 2117-2125. [13] 周苏, 支雪磊, 刘懂, 等. 基于卷积神经网络的小目标交通标志检测算法[J]. 同济大学学报(自然科学版), 2019, 47(11): 1626-1632. doi: 10.11908/j.issn.0253-374x.2019.11.012ZHOU Su, ZHI Xue-lei, LIU Dong, et al. A convolutional neural network-based method for small traffic sign detection[J]. Journal of Tongji University (Natural Science), 2019, 47(11): 1626-1632. (in Chinese) doi: 10.11908/j.issn.0253-374x.2019.11.012 [14] HONG S, ROH B, KIM H, et al. PVANet: lightweight deep neural networks for real-time object detection[EB/OL]. (2016-12-09)[2022-07-02]. https://arxiv.org/abs/1611.08588. [15] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 779-788. [16] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 7263-7271. [17] REDMON J, FARHADI A. YOLOv3: an incremental improvement[R]. Ithaca: Cornell University, 2018. [18] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]//Springer. 14th European Conference on Computer Vision. Berlin: Springer, 2016: 21-37. [19] FU Cheng-yang, LIU Wei, RANGA A, et al. DSSD: Deconvolutional single shot detector[J]. arXiv, 2017: 20200017371. [20] RAJENDRAN S P, SHINE L, PRADEEP R, et al. Real-time traffic sign recognition using yolov3 based detector[C]//IEEE. 10th International Conference on Computing, Communication and Networking Technologies. New York: IEEE, 2019: 1-7. [21] STALLKAMP J, SCHLIPSING M, SALMEN J, et al. The German traffic sign recognition benchmark: A multi-class classification competition[C]//IEEE. 2011 International Joint Conference on Neural Networks. New York: IEEE, 2011: 1453-1460. [22] ZHANG Hui-bing, QIN Long-fei, LI Jun, et al. Real-time detection method for small traffic signs based on YOLOv3[J]. IEEE Access, 2020, 8: 64145-64156. doi: 10.1109/ACCESS.2020.2984554 [23] ZHANG Hong-yi, CISSE M, DAUPHIN Y N, et al. Mixup: beyond empirical risk minimization[EB/OL]. (2018-04-27)[2022-07-02]. https://arxiv.org/abs/1710.09412. [24] WU Yi-qiang, LI Zhi-yong, CHEN Ying, et al. Real-time traffic sign detection and classification towards real traffic scene[J]. Multimedia Tools and Applications, 2020, 79(25/26): 18201-18219. [25] HE Kai-ming, ZHANG Xiang-yu, REN Shao-qing, et al. Deep residual learning for image recognition[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 770-778. [26] REZATOFIGHI H, TSOI N, GWAK J Y, et al. Generalized intersection over union: A metric and a loss for bounding box regression[C]//IEEE. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 658-666. [27] 高涛, 刘梦尼, 陈婷, 等, 等. 结合暗亮通道先验的远近景融合去雾算法[J]. 西安交通大学学报, 2021, 55(10): 78-86. https://www.cnki.com.cn/Article/CJFDTOTAL-XAJT202110009.htmGAO Tao, LIU Meng-ni, CHEN Ting, et al. A far and near scene fusion defogging algorithm based on the prior of dark-light channel[J]. Journal of Xi'an Jiaotong University, 2021, 55(10): 78-86. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-XAJT202110009.htm [28] ŽALIK K R. An efficient k'-means clustering algorithm[J]. Pattern Recognition Letters, 2008, 29(9): 1385-1391. doi: 10.1016/j.patrec.2008.02.014 [29] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]//Springer. 13th European conference on computer vision. Berlin: Springer, 2014: 740-755. [30] EVERINGHAM M, VAN L, CHRISTOPHER W, et al. The pascal visual object classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303-338. -





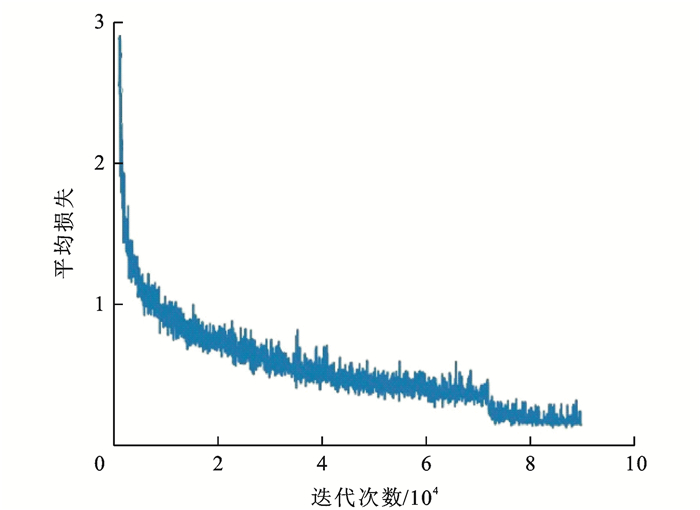







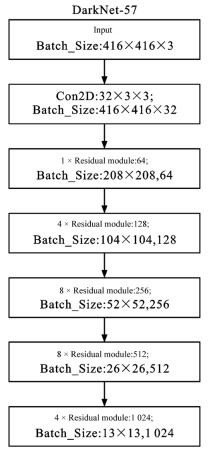
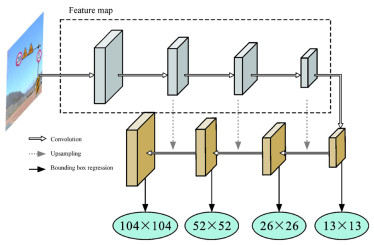










 点击查看大图
点击查看大图
计量
- 文章访问数: 1038
- HTML全文浏览量: 396
- PDF下载量: 91
- 被引次数: 0
