

A fused network based on PReNet and YOLOv4 for traffic object detection in rainy environment
-
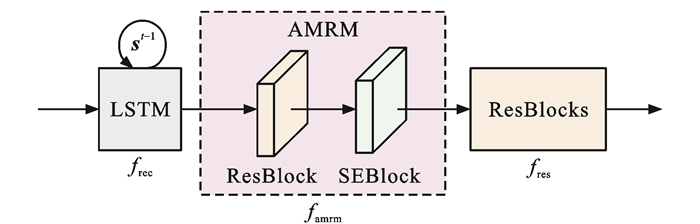
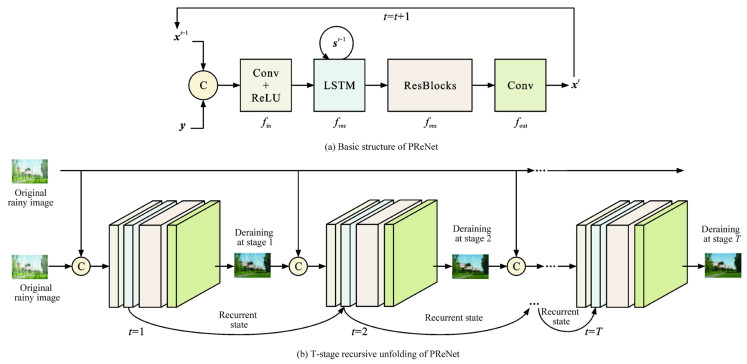
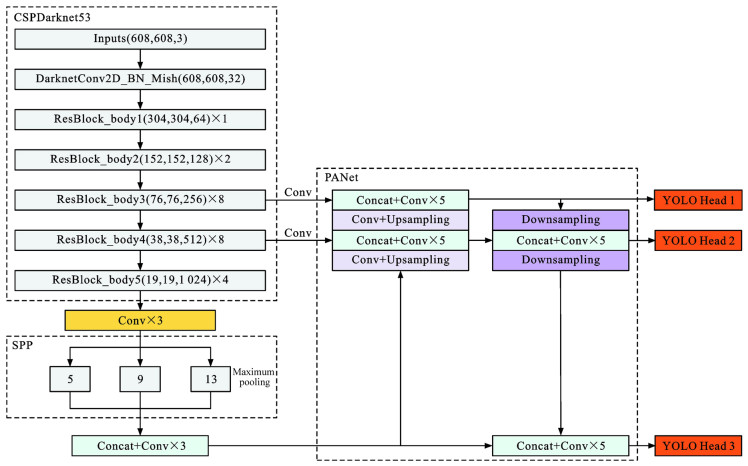
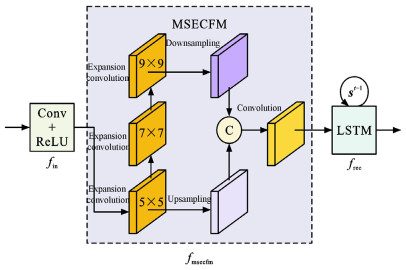
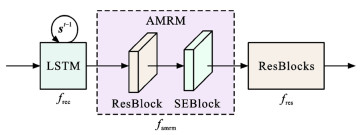
摘要: 为提高恶劣雨天交通环境下车辆目标检测精度,提出一种基于PReNet和YOLOv4融合的深度学习网络DTOD-PReYOLOv4,融合了改进的图像复原子网D-PReNet和改进的目标检测子网TOD-YOLOv4;将多尺度膨胀卷积融合模块和添加了挤压激励块的注意机制残差模块引入PReNet,获得的D-PReNet可更有效提取雨纹特征; 使用轻量化的CSPDarknet26代替YOLOv4骨干模块CSPDarknet53,为YOLOv4的颈部路径聚合网络模块添加复合残差块,同时采用k-means++算法取代原始网络聚类算法,获得的TOD-YOLOv4可在改善交通小目标检测精度的同时进一步提高检测效率; 基于构建的雨天交通场景车辆目标数据集VOD-RTE对DTOD-PReYOLOv4进行了验证。研究结果表明:与当前YOLO系列主流网络相比,提出的DTOD-PReYOLOv4对原浅层ResBlock_body1叠加残差块,可以更好地提取分辨率较小的特征; 对原深层ResBlock_body3、ResBlock_body4和ResBlock_body5进行裁剪,获得ResBlock_body3×2、ResBlock_body4×2和ResBlock_body5×2,可以有效降低卷积层冗余,提高内存利用率; 为PANet中的Concat+Conv×5添加跳跃连接形成CRB模块,可以有效缓解网络层数加深引起的小目标检测效果退化问题; 采用k-means++算法,在多尺度检测过程中为较大的特征图分配更加适合的较小先验框,为较小的特征图分配更加适合的较大先验框,进一步提高了目标检测的精度; 与MYOLOv4相比,精确率和召回率的调和平均值、平均精度、检测速度分别提升了5.02%、6.70%、15.63帧·s-1,与TOD-YOLOv4相比,分别提升了3.51%、4.31%、2.17帧·s-1,与YOLOv3相比,分别提升了46.07%、48.05%、18.97帧·s-1,与YOLOv4相比,分别提升了31.06%、29.74%、16.26帧·s-1。Abstract: In order to improve the detection accuracy of vehicle target in severe rainy day under traffic environment, a deep learning network DTOD-PReYOLOv4 (derain and traffic object detection-PReNet and YOLOv4) was proposed based on the fusion of PReNet and YOLOv4, which integrated the improved image restoration subnet D-PReNet and the improved target detection subnet TOD-YOLOv4. D-PReNet could extract rain streak features more effectively, since it introduced the multi-scale expansion convolution fusion module (MSECFM) and the attentional mechanism residual module (AMRM) with SEBlock into PReNet. TOD-YOLOv4 improved not only the detection accuracy of small traffic target, but also the detection efficiency, since it replaced the backbone module CSPDarknet53 of YOLOv4 with the lightweight CSPDarknet26 of YOLOv4, added CRB into PANet of YOLOv4 neck, and utilized k-means++ instead of the original network clustering algorithm. DTOD-PReYOLOv4 was verified based on the constructed vehicle target database VOD-RTE in rainy day traffic scenario. Research results show that compared with the current series of YOLO networks, the proposed DTOD-PReYOLOv4 can better extract the features with lower resolutions by superimposing RB over ResBlock_body1 in the shallow layer. It can effectively reduce the convolutional layer redundancy and improve the memory utilization, since ResBlock_body3, ResBlock_body4 and ResBlock_body5 in deep layer can be properly cropped to ResBlock_body3×2, ResBlock_body4×2 and ResBlock_body5×2, respectively. It also can alleviate the degradation of small target detection effect caused by the deepening of network layers by adding jump connection to Concat+Conv×5 in PANet to form CRB. In the process of multi-scale detection, k-means++ algorithm is adopted to allocate smaller prior boxes that are more suitable for the larger feature images, but larger prior boxes that are more suitable for smaller feature images, which further improves the accuracy of target detection. The harmonic mean value of precision and recall rate, average precision and detection speed of DTOD-PReYOLOv4 respectively increase by 5.02%, 6.70% and 15.63 frames per second compared with MYOLOv4, by 3.51%, 4.31% and 2.17 frames per second compared with TOD-YOLOv4, by 46.07%, 48.05% and 18.97 frames per second compared with YOLOv3, and by 31.06%, 29.74% and 16.26 frames per second compared with YOLOv4. 4 tabs, 12 figs, 44 refs.
-
Key words:
- intelligent transportation /
- object detection /
- YOLOv4 /
- PReNet /
- attentional mechanism /
- multi-scale detection
-

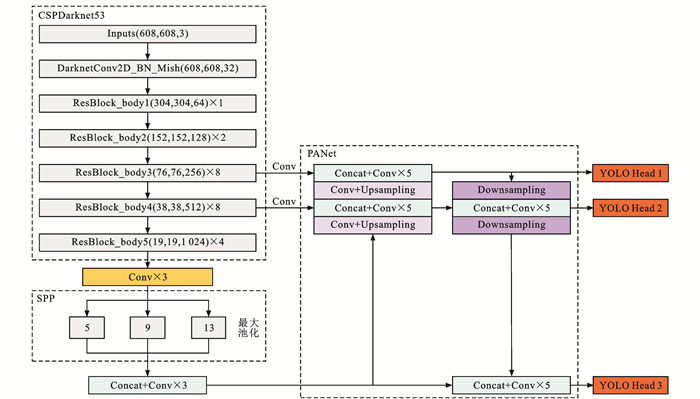
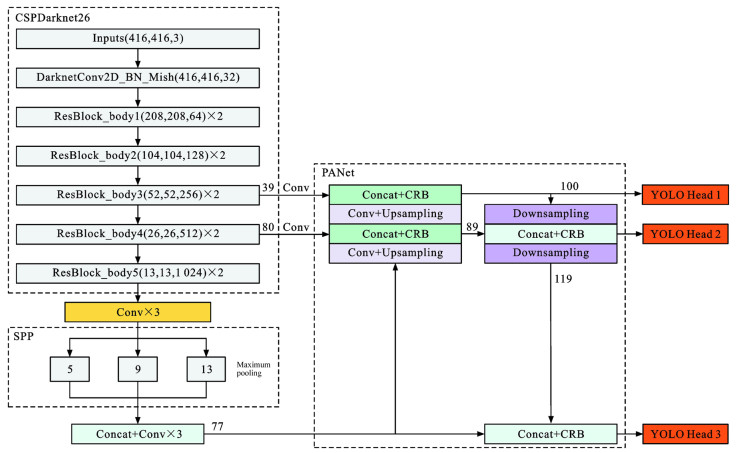
图 3 雨天交通目标检测网络DTOD-YOLOv4
Figure 3. Network DTOD-YOLOv4 of traffic object detection in rainy environment

图 12 真实雨天交通场景下的车辆目标检测结果对比
Figure 12. Comparison of vehicle object detection results in real rainy traffic scene

12. Comparison of results of vehicle object detection in traffic scenes in real rainy environments
表 1 CSPDarknet26网络参数
Table 1. Network parameters of CSPDarknet26
网络分层 卷积核个数 卷积核尺度 输出分辨率/pixel Conv 32 3×3 416×416 Conv 64 3×3/2 208×208 ResBlock_body1×2 32 1×1 208×208 64 3×3 Conv 128 3×3/2 104×104 ResBlock_body2×2 64 1×1 104×104 128 3×3 Conv 256 3×3/2 52×52 ResBlock_body3×2 128 1×1 52×52 256 3×3 Conv 512 3×3/2 26×26 ResBlock_body4×2 256 1×1 26×26 512 3×3 Conv 1 024 3×3/2 13×13 ResBlock_body5×2 512 1×1 13×13 1 024 3×3  下载: 导出CSV
下载: 导出CSV
表 2 Car型锚点框信息示例
Table 2. Examples of car anchor box information
标签名称 Xmin/pixel Ymin/pixel Xmax/pixel Ymax/pixel Car 1 312 609 417 701 Car 2 389 600 480 672 Car 3 685 549 767 612 Car 4 510 503 573 539 Car 5 521 463 572 510 Car 6 488 389 528 427 Car 7 526 381 568 409
下载: 导出CSV
表 3 车辆检测结果
Table 3. Vehicle detection result
网络 YOLOv3 YOLOv4 MYOLOv4 TOD-YOLOv4 DTOD-PReYOLOv4 车辆总数 9 9 9 9 9 检出车辆数 1 4 5 6 9 漏检车辆数 8 5 4 3 0 误检车辆数 0 1 0 0 0
下载: 导出CSV
表 4 目标检测评价结果
Table 4. Evaluation result of object detection
网络 P/% R/% F/% $\bar P $ /% S/(帧·s-1) YOLOv3 35.00 76.00 47.93 45.56 32.13 YOLOv4 49.00 88.00 62.94 63.87 34.84 MYOLOv4 88.00 90.00 88.98 86.91 35.47 TOD-YOLOv4 90.00 91.00 90.49 89.30 48.93 DTOD-PReYOLOv4 96.00 91.00 94.00 93.61 51.10
下载: 导出CSV
1. Network parameters of CSPDarkNet26

2. Examples of information on Car-type anchor boxes

3. Vehicle detection result

4. Result of object detection evaluation

-
[1] 唐立, 卿三东, 徐志刚, 等. 自动驾驶公众接受度研究综述[J]. 交通运输工程学报, 2020, 20(2): 131-146. https://www.cnki.com.cn/Article/CJFDTOTAL-JYGC202002011.htmTANG Li, QING San-dong, XU Zhi-gang, et al. Research review on public acceptance of autonomous driving[J]. Journal of Traffic and Transportation Engineering, 2020, 20(2): 131-146. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-JYGC202002011.htm [2] 缪炳荣, 张卫华, 刘建新, 等. 工业4.0下智能铁路前沿技术问题综述[J]. 交通运输工程学报, 2021, 21(1): 115-131. https://www.cnki.com.cn/Article/CJFDTOTAL-JYGC202101008.htmMIAO Bing-rong, ZHANG Wei-hua, LIU Jian-xin, et al. Review on frontier technical issues of intelligent railways under industry 4.0[J]. Journal of Traffic and Transportation Engineering, 2021, 21(1): 115-131. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-JYGC202101008.htm [3] 杨澜, 赵祥模, 吴国垣, 等. 智能网联汽车协同生态驾驶策略综述[J]. 交通运输工程学报, 2020, 20(5): 58-72. https://www.cnki.com.cn/Article/CJFDTOTAL-JYGC202005008.htmYANG Lan, ZHAO Xiang-mo, WU Guo-yuan, et al. Review on connected and automated vehicles based cooperative eco-driving strategies[J]. Journal of Traffic and Transportation Engineering, 2020, 20(5): 58-72. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-JYGC202005008.htm [4] 马永杰, 马芸婷, 程时升, 等. 基于改进YOLOv3模型与Deep-SORT算法的道路车辆检测方法[J]. 交通运输工程学报, 2021, 21(2): 222-231. https://www.cnki.com.cn/Article/CJFDTOTAL-JYGC202102022.htmMA Yong-jie, MA Yun-ting, CHENG Shi-sheng, et al. Road vehicle detection method based on improved YOLOv3 model and deep-SORT algorithm[J]. Journal of Traffic and Transportation Engineering, 2021, 21(2): 222-231. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-JYGC202102022.htm [5] ZHANG He, PATEL V M. Density-aware single image de-raining using a multi-stream dense network[C]//IEEE. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 695-704. [6] LI Xia, WU Jian-long, LIN Zhou-chen, et al. Recurrent squeeze-and-excitation context aggregation net for single image deraining[C]//Springer. 2014 European Conference on Computer Vision. Berlin: Springer, 2018: 262-277. [7] REN D, ZUO W, HU Q, et al. Progressive image deraining networks: A better and simpler baseline[C]//IEEE. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 3932-3941. [8] JIN Xin, CHEN Zhi-bo, LI Wei-ping. AI-GAN: asynchronous interactive generative adversarial network for single image rain removal[J]. Pattern Recognition, 2020, 100: 107143. doi: 10.1016/j.patcog.2019.107143 [9] 柳长源, 王琪, 毕晓君. 基于多通道多尺度卷积神经网络的单幅图像去雨方法[J]. 电子与信息学报, 2020, 42(9): 2285-2292. https://www.cnki.com.cn/Article/CJFDTOTAL-DZYX202009027.htmLIU Chang-yuan, WANG Qi, BI Xiao-jun. Research on rain removal method for single image based on multi-channel and multi-scale CNN[J]. Journal of Electronics and Information Technology, 2020, 42(9): 2285-2292. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-DZYX202009027.htm [10] LIN Xiao, MA Li-zhuang, SHENG Bin, et al. Utilizing two-phase processing with FBLS for single image deraining[J]. IEEE Transactions on Multimedia, 2020, 23: 664-676. [11] PENG Jia-yi, XU Yong, CHEN Tian-yi, et al. Single-image raindrop removal using concurrent channel-spatial attention and long-short skip connections[J]. Pattern Recognition Letters, 2020, 131: 121-127. doi: 10.1016/j.patrec.2019.12.012 [12] SUN Guo-min, LENG Jin-song, CATTANI C. A particular directional multilevel transform based method for single-image rain removal[J]. Knowledge-Based Systems, 2020, 200: 106000. doi: 10.1016/j.knosys.2020.106000 [13] PENG Long, JIANG Ai-wen, Yi Qiao-si, et al. Cumulative rain density sensing network for single image Derain[J]. IEEE Signal Processing Letters, 2020, 27: 406-410. doi: 10.1109/LSP.2020.2974691 [14] BI Xiao-jun, XING Jun-yao. Multi-scale weighted fusion attentive generative adversarial network for single image de-raining[J]. IEEE Access, 2020, 8: 69838-69848. doi: 10.1109/ACCESS.2020.2983436 [15] WANG Hong, WU Yi-chen, XIE Qi, et al. Structural residual learning for single image rain removal[J]. Knowledge-Based Systems, 2021, 213: 106595. doi: 10.1016/j.knosys.2020.106595 [16] 高涛, 刘梦尼, 陈婷, 等. 结合暗亮通道先验的远近景融合去雾算法[J]. 西安交通大学学报, 2021, 55(10): 78-86. https://www.cnki.com.cn/Article/CJFDTOTAL-XAJT202110009.htmGAO Tao, LIU Meng-ni, CHEN Ting, et al. A far and near scene fusion defogging algorithm based on the prior of dark-light channel[J]. Journal of Xi'an Jiaotong University, 2021, 55(10): 78-86. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-XAJT202110009.htm [17] CHEN Ting, LIU Meng-ni, GAO Tao, et al. A fusion-based defogging algorithm[J]. Remote Sensing, 2022, 14(2): 425. doi: 10.3390/rs14020425 [18] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 779-788. [19] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 6517-6525. [20] REDMON J, FARHADI A. YOLOv3: An incremental improvement[J]. arXiv, 2018: 20200100292. [21] BOCHKOVSKIY A, WANG Chien-yao, LIAO Hong-yuan. YOLOv4: optimal speed and accuracy of object detection[J]. arXiv, 2020: 20200411830. [22] NING Zhang, MI Zhi-wei. Research on surface defect detection algorithm of strip steel based on improved YOLOv3[J]. Journal of Physics: Conference Series, 2021, 1907(1): 012015. doi: 10.1088/1742-6596/1907/1/012015 [23] YU Pei-dong, WANG Xin, LIU Jian-hui, et al. Bridge target detection in remote sensing image based on improved YOLOv4 algorithm[C]//ACM. 2020 4th International Conference on Computer Science and Artificial Intelligence. New York: ACM, 2020: 139-145. [24] CHEN Wen-kang, LU Sheng-lian, LIU Bing-hao, et al. Detecting citrus in orchard environment by using improved YOLOv4[J]. Scientific Programming, 2020, 2020: 8859237. [25] ZHU Qin-feng, ZHENG Hui-feng, WANG Yue-bing, et al. Study on the evaluation method of sound phase cloud maps based on an improved YOLOv4 algorithm[J]. Sensors, 2020, 20(15): 4314. doi: 10.3390/s20154314 [26] HU Jie, SHEN Li, ALBANIE S. Squeeze-and-excitation networks[C]// IEEE. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 7132-7141. [27] DENG Jie, DONG Wei, SOCHER R, et al. Imagenet: A large-scale hierarchical image database[C]//IEEE. 2009 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2009: 248-255. [28] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]//Springer. 13th European Conference on Computer Vision. Berlin: Springer, 2014: 740-755. [29] ARTHUR D, VASSILVITSKⅡ S. k-means++: the advantages of careful seeding[C]//ACM. 18th Annual ACM-SIAM Symposium on Discrete Algorithms. New York: ACM, 2007: 1027-1035. [30] CHOWDHURY K, CHAUDHURI D, PAL A K, et al. Seed selection algorithm through k-means on optimal number of clusters[J]. Multimedia Tools and Applications, 2019, 78(13): 18617-18651. doi: 10.1007/s11042-018-7100-4 [31] YAMAMICHI K, HAN Xian-hua. MCGKT-Net: Multi-level context gating knowledge transfer network for single image deraining[C]//Springer. 15th Asian Conference on Computer Vision. Berlin: Springer, 2020: 1-17. [32] YANG Wen-han, TAN R T, FENG Jia-shi, et al. Deep joint rain detection and removal from a single image[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 1357-1366. [33] LI Yu, TAN Robby T, GUO Xiao-jie, et al. Rain streak removal using layer priors[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 2736-2744. [34] ZHANG He, SINDAGI V, PATEL V M. Image de-raining using a conditional generative adversarial network[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2020, 30(11): 3943-3956. doi: 10.1109/TCSVT.2019.2920407 [35] FU Xue-yang, HUANG Jia-bin, ZENG De-lu, et al. Removing rain from single images via a deep detail network[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 3855-3863. [36] ZHANG He, PATEL V M. Density-aware single image de-raining using a multi-stream dense network[C]//IEEE. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 695-704. [37] GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? the KITTI vision benchmark suite[C]//IEEE. 25th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2012: 3354-3361. [38] CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 3213-3223. [39] NEUHOLD G, OLLMANN T, BULÒ S R, et al. The mapillary vistas dataset for semantic understanding of street scenes[C]//IEEE. 30th IEEE International Conference on Computer Vision. New York: IEEE, 2017: 4990-4999. [40] YU Fisher, XIAN Wen-qi, CHEN Ying-ying, et al. BDD100K: a diverse driving video database with scalable annotation tooling[EB/OL]. (2020-04-08)[2022-07-02]. https://arxiv.org/abs/1805.04687v2. [41] CAESAR H, BANKITI V, LANG A H, et al. nuScenes: a multimodal dataset for autonomous driving[C]//IEEE. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2020: 11618-11628. [42] HUANG Xin-yu, WANG Peng, CHENG Xin-jing, et al. The ApolloScape open dataset for autonomous driving and its application[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(10): 2702-2719. doi: 10.1109/TPAMI.2019.2926463 [43] ZHU Zhe, LIANG Dun, ZHANG Song-hai, et al. Traffic-sign detection and classification in the wild[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 2110-2118. [44] STALLKAMP J, SCHLIPSING M, SALMEN J, et al. The German traffic sign recognition benchmark: a multi-class classification competition[C]// IEEE. 2011 International Joint Conference on Neural Networks. New York: IEEE, 2011: 1453-1460. -















 点击查看大图
点击查看大图
计量
- 文章访问数: 1534
- HTML全文浏览量: 587
- PDF下载量: 207
- 被引次数: 0
