

Perception of moving objects in traffic scenes based on heterogeneous graph learning
-
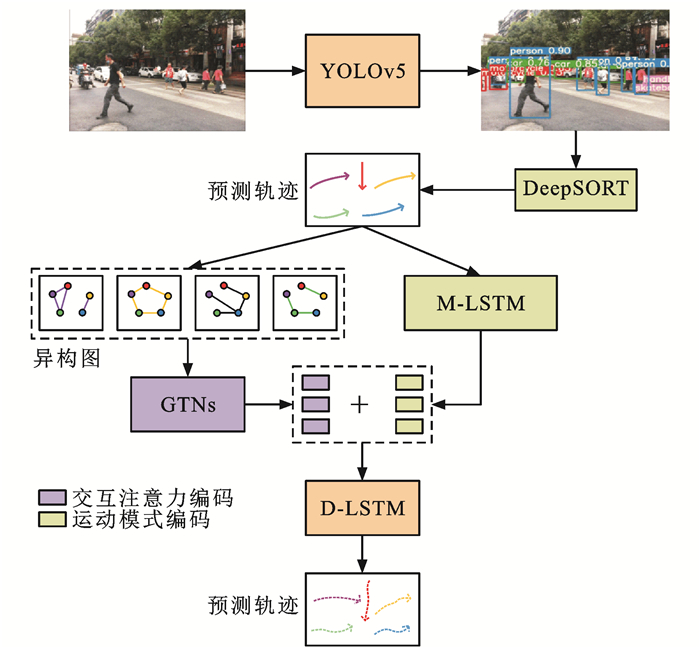
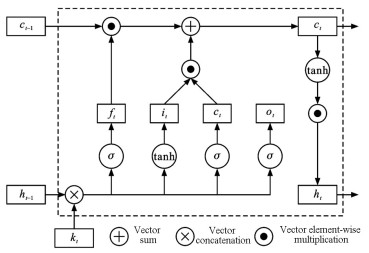
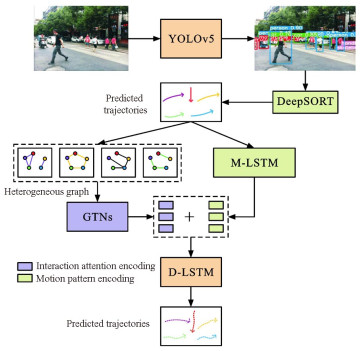
摘要: 为了提高无人车在交通场景中的运行效率和运输安全,研究了基于异构图学习的交通场景运动目标感知; 考虑实际交通场景中运动目标之间的复杂交互关系对目标运动的影响,基于异构图学习提出了交通场景中多目标检测-跟踪-预测一体化感知框架; 结合YOLOv5和DeepSORT检测并跟踪运动目标,获得目标的运动轨迹; 使用长短期记忆(LSTM)网络从目标历史轨迹中学习目标的运动信息,使用异构图学习目标间的交互信息,以提高运动目标轨迹预测准确度; 使用LSTM网络对目标运动信息与交互信息解码得到目标未来轨迹; 为了验证方法的有效性,在公共交通数据集Argoverse、Apollo和NuScenes上进行了评估。分析结果表明:结合YOLOv5和DeepSORT可实现对运动目标的检测跟踪,对交通场景中的运动目标实现了75.4%的正确检测率和61.4%的连续跟踪率; 异构图能够有效捕捉运动目标之间复杂的交互关系,并且捕捉的交互关系能够提高轨迹预测精度,加入异构图捕捉交互关系后,运动目标的平均位移预测误差降低了63.0%。可见,考虑交通场景中运动目标之间的交互关系是有效的,引入异构图学习运动目标之间的交互关系可以感知运动目标的历史与未来运动信息,从而帮助无人车更好地理解复杂交通场景。Abstract: In order to improve the operation efficiency and transportation safety of unmanned vehicles in traffic scenes, the perception of moving objects in traffic scenes was investigated based on the heterogeneous graph learning.In view of the influence of complex interaction relations between moving objects on their motions in actual traffic scenes, an integrated perception framework of multi-object detection-tracking-prediction was proposed based on the heterogeneous graph learning. YOLOv5 and DeepSORT were combined to detect and track the moving objects, and the trajectories of the objects were obtained. The long short-term memory (LSTM) network was used to learn the objects' motion information from their historical trajectories, and a heterogeneous graph was introduced to learn the interaction information between the objects and improve the prediction accuracies of the trajectories of moving objects. The LSTM network was also utilized to decode the objects' motion and interaction information to obtain their future trajectories, and the method was evaluated on the public transportation datasets Argoverse, Apollo, and NuScenes to verify its effectiveness.Analysis results show that the combination of YOLOv5 and DeepSORT can realize the detection and tracking of moving objects and achieve a detection accuracy rate of 75.4% and a continuous tracking rate of 61.4% for moving objects in traffic scenes. The heterogeneous graph can effectively capture the complex interaction relations between moving objects, and the captured interaction relations can improve the accuracy of trajectory prediction. The error of the predicted average displacement of moving objects reduces by 63.0% after the interaction relations captured by the heterogeneous graph are added. As a result, it is effective to consider the interaction relations between moving objects in traffic scenes. The historical and future motion information of moving objects can be perceived by introducing the heterogeneous graph to capture the interaction relations between moving objects, so as to facilitate unmanned vehicles to better understand complex traffic scenes. 4 tabs, 9 figs, 36 refs.
-

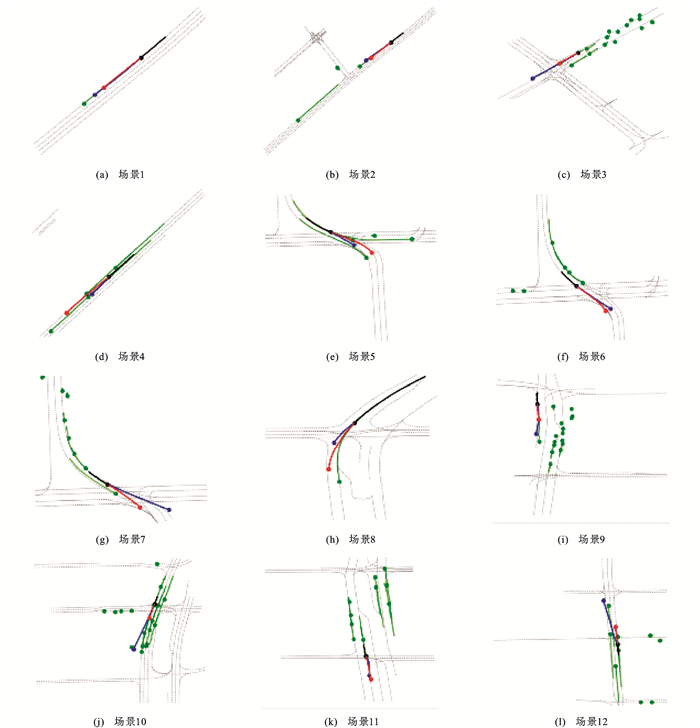
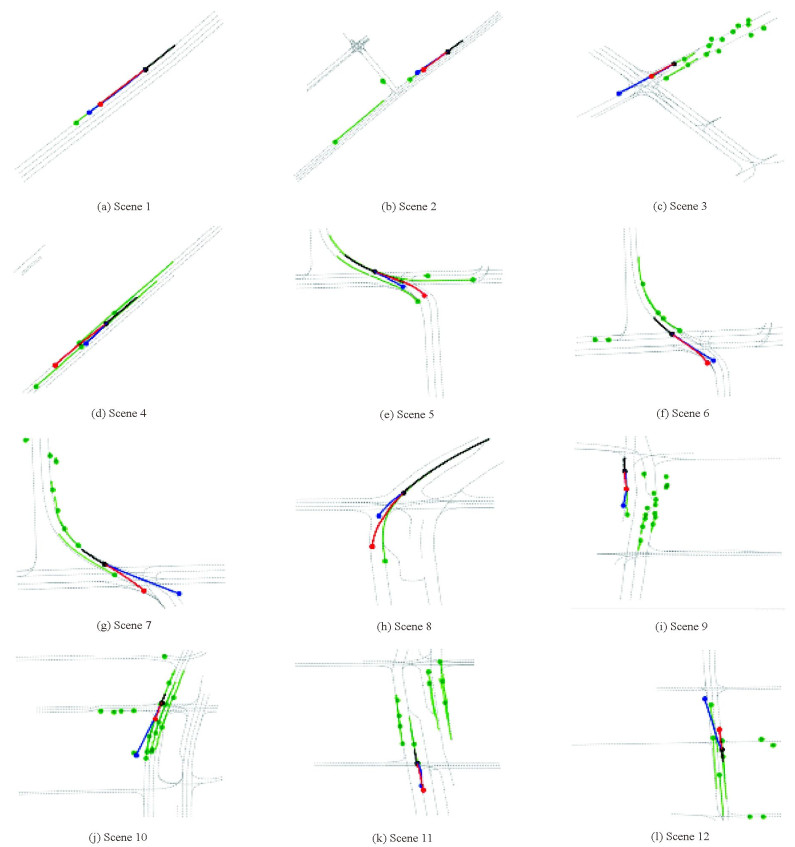
图 8 Argoverse数据集上轨迹预测可视化
Figure 8. Visualization of trajectory prediction on Argoverse database

图 9 Apollo数据集上轨迹预测可视化
Figure 9. Visualization of trajectory prediction on Apollo database
表 1 销蚀试验结果(Apollo/Argoverse)
Table 1. Ablation test results(Apollo/Argoverse)
卡尔曼滤波 运动模式编码 运动目标交互编码 ADE √ 14.31/2.94 √ 8.58/2.61 √ √ 4.26/2.49  下载: 导出CSV
下载: 导出CSV
表 2 Faster R-CNN与YOLOv5对比
Table 2. Comparison between Faster R-CNN and YOLOv5
算法 MAP/% FPS/Hz FLOPs/B Faster R-CNN 67.0 21.7 23.0 YOLOv5 75.4 52.8 17.0
下载: 导出CSV
表 3 SORT与DeepSORT对比
Table 3. Comparison between SORT and DeepSORT
算法 MOTA MOTP MT/% ML/% FPS/Hz SORT 59.8 79.6 25.4 22.7 60 DeepSORT 61.4 79.1 32.8 18.2 40
下载: 导出CSV
表 4 不同轨迹预测算法在3个公共数据集上的性能对比(ADE/FDE)
Table 4. Performance comparison among different trajectory prediction methods on three public databases (ADE/FDE)
算法 Argoverse Apollo NuScenes CVM 3.19/7.09 25.01/55.40 4.77/6.87 LSTM 2.61/5.52 8.58/16.04 2.62/4.33 SGAN 2.53/7.85 16.41/29.79 1.77/3.87 NMMP 2.57/7.43 12.90/25.28 2.21/3.89 Social-STGCNN 2.54/6.78 4.60/5.68 1.32/2.43 DTPP 2.49/5.35 4.26/7.58 1.25/2.21
下载: 导出CSV
1. Ablation experiment results (Apollo/Argoverse)

2. Comparison between faster R-CNN and YOLOv5

3. Comparison between SORT and DeepSORT

4. Performance comparison among different trajectory prediction algorithms on three public databases (ADE/FDE)

-
[1] CHEN Xiao-zhi, KUNDU K, ZHANG Z, et al. Monocular 3D object detection for autonomous driving[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 2147-2156. [2] XU Bin, CHEN Zhen-zhong. Multi-level fusion based 3D object detection from monocular images[C]//IEEE. 31th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 2345-2353. [3] WANG Yan, CHAO Wei-lun, GARG D, et al. Pseudo-lidar from visual depth estimation: bridging the gap in 3D object detection for autonomous driving[C]//IEEE. 32th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 8445-8453. [4] LIU Ze, CAI Ying-feng, WANG Hai, et al. Robust target recognition and tracking of self-driving cars with radar and camera information fusion under severe weather conditions[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 23(7): 6640-6653. [5] WANG Nai-yan, YEUNG D Y. Learning a deep compact image representation for visual tracking[J]. Advances in Neural Information Processing Systems, 2013, 26(1): 809-817. [6] TAO Ran, GAVVES E, SMEULDERS A W M. Siamese instance search for tracking[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 1420-1429. [7] NAM H, HAN B. Learning multi-domain convolutional neural networks for visual tracking[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 4293-4302. [8] YANG Biao, ZHAN Wei-qin, WANG Pin, et al. Crossing or not? Context-based recognition of pedestrian crossing intention in the urban environment[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(8): 5338-5349. [9] WANG Li-jun, OUYANG Wan-li, WANG Xiao-gang, et al. Visual tracking with fully convolutional networks[C]//IEEE. 15th International Conference on Computer Vision. New York: IEEE, 2015: 3119-3127. [10] LEE N, CHOI W, VERNAZA P, et al. Desire: distant future prediction in dynamic scenes with interacting agents[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 336-345. [11] GUPTA A, JOHNSON J, LI Fei-fei, et al. Social GAN: socially acceptable trajectories with generative adversarial networks[C]//IEEE. 31th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 2255-2264. [12] WALKER J, DOERSCH C, GUPTA A, et al. An uncertain future: forecasting from static images using variational autoencoders[C]//Springer. 14th European Conference on Computer Vision. Berlin: Springer, 2016: 835-851. [13] CAI Ying-feng, DAI Lei, WANG Hai, et al. Pedestrian motion trajectory prediction in intelligent driving from far shot first-person perspective video[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 23(6): 5298-5313. [14] GIULIARI F, HASAN I, CRISTANI M, et al. Transformer networks for trajectory forecasting[C]//IEEE. 25th International Conference on Pattern Recognition. New York: IEEE, 2021: 10335-10342. [15] KITANI K M, ZIEBART B D, BAGNELL J A, et al. Activity forecasting[C]//Springer. 10th European Conference on Computer Vision. Berlin: Springer, 2012: 201-214. [16] LUO Wen-jie, YANG Bin, URTASUN R. Fast and furious: real time end-to-end 3d detection, tracking and motion forecasting with a single convolutional net[C]//IEEE. 31th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 3569-3577. [17] LIANG Ming, YANG Bin, ZENG Wen-yuan, et al. PnPNet: end-to-end perception and prediction with tracking in the loop[C]//IEEE. 33th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 11553-11562. [18] SHI Xing-jian, CHEN Zhou-rong, WANG Hao, et al. Convolutional LSTM network: a machine learning approach for precipitation nowcasting[J]. Advances in Neural Information Processing Systems, 2015, 28(1): 802-810. [19] ALAHI A, GOEL K, RAMANATHAN V, et al. Social LSTM: human trajectory prediction in crowded spaces[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 961-971. [20] MA W C, HUANG D A, LEE N, et al. Forecasting interactive dynamics of pedestrians with fictitious play[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 774-782. [21] BISAGNO N, ZHANG B, CONCI N. Group LSTM: group trajectory prediction in crowded scenarios[C]//Springer. 16th European Conference on Computer Vision. Berlin: Springer, 2018: 213-225. [22] 杨彪, 范福成, 杨吉成, 等. 基于动作预测与环境条件的行人过街意图识别[J]. 汽车工程, 2021, 43(7): 1066-1076. https://www.cnki.com.cn/Article/CJFDTOTAL-QCGC202107015.htmYANG Biao, FAN Fu-cheng, YANG Ji-cheng, et al. Recognition of pedestrians' street-crossing intentions based on action prediction and environment context[J]. Automotive Engineering, 2021, 43(7): 1066-1076. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-QCGC202107015.htm [23] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 7263-7271. [24] WOJKE N, BEWLEY A, PAULUS D. Simple online and realtime tracking with a deep association metric[C]//IEEE. 24th IEEE International Conference on Image Processing (ICIP). New York: IEEE, 2017: 3645-3649. [25] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//IEEE. 27th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2014: 580-587. [26] GIRSHICK R. Fast R-CNN[C]//IEEE. 19th International Conference on Pattern Recognition. New York: IEEE, 2015: 1440-1448. [27] REN Shao-qing, HE Kai-ming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. Advances in Neural Information Processing Systems, 2015, 28(1): 91-99. [28] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 779-788. [29] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]//Springer. 14th European Conference on Computer Vision. Berlin: Springer, 2016: 21-37. [30] BEWLEY A, GE Zong-yuan, OTT L, et al. Simple online and realtime tracking[C]//IEEE. 23th IEEE International Conference on Image Processing (ICIP). New York: IEEE, 2016: 3464-3468. [31] YUN S, JEONG M, KIM R, et al. Graph transformer networks[J]. Advances in Neural Information Processing Systems, 2019, 32(1): 11983-11993. [32] CHANG Ming-fang, LAMBERT J, SANGKLOY P, et al. Argoverse: 3D tracking and forecasting with rich maps[C]//IEEE. 32th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 8748-8757. [33] MA Yue-xin, ZHU X, ZHANG Si-bo, et al. Traffic predict: trajectory prediction for heterogeneous traffic-agents[C]//AAAI. 33th AAAI Conference on Artificial Intelligence. Menlo Park : AAAI, 2019: 6120-6127. [34] CAESAR H, BANKITI V, LANG A H, et al. NuScenes: a multimodal dataset for autonomous driving[C]//IEEE. 33th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 11621-11631. [35] HU Yue, CHEN Si-heng, ZHANG Ya, et al. Collaborative motion prediction via neural motion message passing[C]//IEEE. 33th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 6319-6328. [36] MOHAMED A, QIAN KU N, ELHOSEINY M, et al. Social-STGCNN: a social spatio-temporal graph convolutional neural network for human trajectory prediction[C]//IEEE. 33th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 14424-14432. -










 点击查看大图
点击查看大图

计量
- 文章访问数: 684
- HTML全文浏览量: 324
- PDF下载量: 83
- 被引次数: 0
