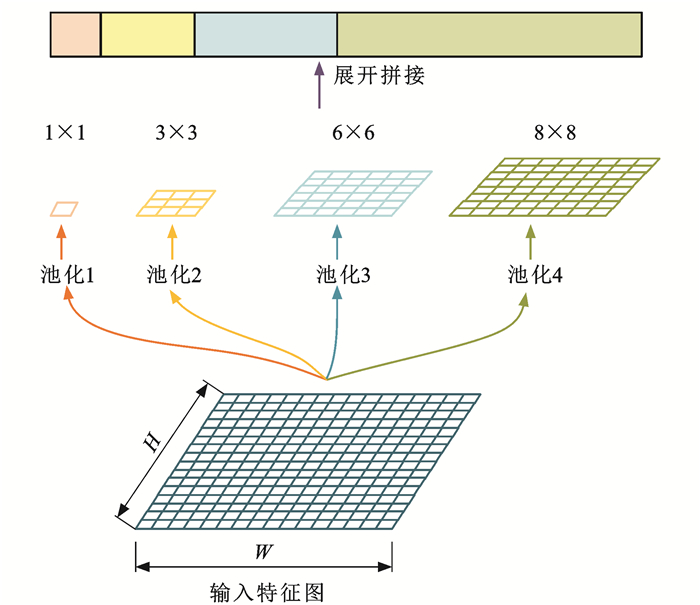
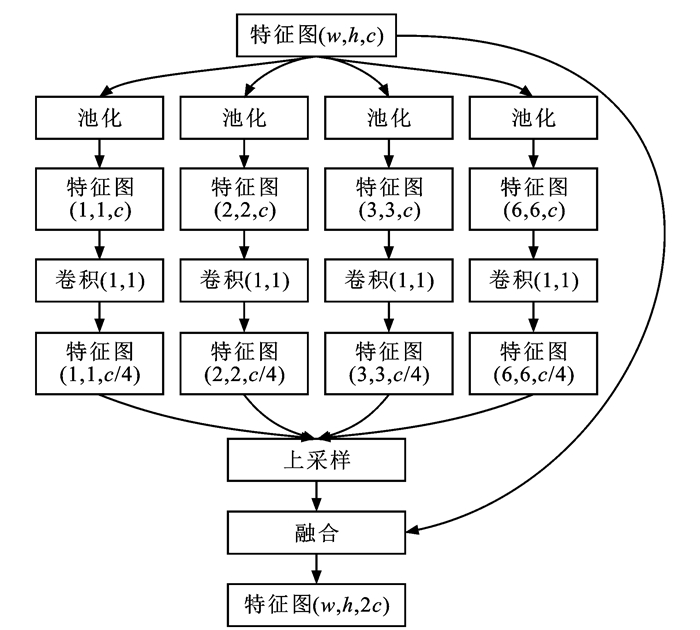
| Citation: | LIU Zhan-wen, FAN Song-hua, QI Ming-yuan, DONG Ming, WANG Pin, ZHAO Xiang-mo. Multi-task perception algorithm of autonomous driving based on temporal fusion[J]. Journal of Traffic and Transportation Engineering, 2021, 21(4): 223-234. doi: 10.19818/j.cnki.1671-1637.2021.04.017

|
In recent years, autonomous driving has been included in the national development strategies of many developed countries. China has also made a series of policy deployments in intelligent connected vehicles, autonomous driving, smart transportation, and other areas, aiming to break through traditional technological bottlenecks, further promote the deep integration of information technologies such as automobiles, artificial intelligence, and communication, and promote the development of the autonomous driving ecosystem industry. Deep learning has achieved excellent results in both object detection and semantic segmentation fields. The DeepLab series of networks proposed by Google Brain in the early days adopted deep learning methods and constantly innovated, making the model make significant breakthroughs in pixel level image segmentation tasks[1-4]Subsequently, Zhao et al[5-6]PSPNet was proposed to introduce a pyramid pooling module on the basis of residual networks, aggregating contextual information based on different regions, improving the network's ability to mine global contextual information, and greatly enhancing the performance of semantic segmentation models; And the proposed real-time segmentation network ICNet greatly shortens the processing time of the semantic segmentation network with minimal loss of segmentation accuracy, enabling the semantic segmentation model to process video streams in real time, making it possible to apply it in the field of autonomous driving. And the object detection model can accurately locate and detect objects in the road environment[7], Ren et al[8]The proposed Faster R-CNN object detection model achieves end-to-end training, greatly accelerating inference speed compared to previous models; Redmon and others[9-11]Propose the YOLO series model, which takes the entire image as an instance to quickly extract feature maps and predict bounding boxes and their corresponding categories. Especially, the accuracy and real-time performance of the YOLOv3 model have become a commonly used solution for object detection in the industrial field.
However, both YOLO series and Faster R-CNN series use anchor boxes to locate target positions, which invisibly introduces many hyperparameters and increases the difficulty of network training. Law, etc[12-13]The proposed model abandons anchor boxes in object detection and instead uses keypoint detection, introducing new ideas for object detection methods and accelerating the inference time of the network, making the object detection model more suitable for real-time tasks such as autonomous driving.
With the continuous development of deep learning, people's focus is no longer on single tasks, but on the hope that deep learning models can process multiple tasks in parallel. Zhao et al[14]A real-time road environment perception model was constructed for autonomous driving scenarios, and pedestrian position detection was achieved by integrating lightweight RPN networks; Teichmann et al[15]A joint classification, detection, and semantic segmentation method has been developed for autonomous driving scenarios. Although it involves multitasking, dividing detection and classification into two sub tasks increases the complexity of the network; Sistu and others[16]A multi task model for autonomous driving scenarios has been proposed, which includes two sub tasks of detection and segmentation. The low-power real-time performance of the model is achieved by sharing the encoder of the two sub tasks; Zhao et al[14-16]The proposed model is also aimed at autonomous driving tasks, but it does not take into account that the input data in autonomous driving tasks is a continuous video stream. Using a single frame image for detection and segmentation will result in the loss of useful information between image frames. At the same time, the multi task network constructed does not analyze the loss proportion of each subtask, and there is a problem of imbalanced loss among multiple tasks during training, which will lead to multiple tasks being unable to achieve optimal results simultaneously; Chen et al[17-20]We conducted in-depth research on this and optimized the weights of various losses through model self-learning, so that there is no situation where a certain subtask dominates training and learning while ignoring other subtasks; When the input data is a video stream, in order to effectively utilize the useful information between image frames, Li et al[21]Propose to select key image frames through adaptive strategies based on DFF, but the model combined with optical flow is only suitable for scenes with slow environmental changes. If applied in rapidly changing scenes, the segmentation accuracy will be greatly reduced, and the calculation cost of optical flow is expensive, resulting in slow network inference speed; Feng et al[22]Designed a fast feature deformation module that uses motion vectors for acceleration, and reduced motion vector noise through residual guided correction and selection modules; Wu et al[23]Proposed the use of attention modules to extract advanced features from non key image frames for fusion, balancing inference speed and accuracy; Feng et al[22-23]Although the proposed models have improved segmentation performance, they all come at the cost of sacrificing accuracy and achieving faster network processing speeds.
In response to the problem that existing perception algorithms cannot balance detection accuracy and inference speed, this paper adopts a stable residual network as the backbone network, considers the potential relationship between image frames, and constructs a backbone network based on temporal fusion to extract features from continuous video data; Add cascaded feature fusion modules to the backbone network to maximize the accuracy of video stream processing while meeting real-time processing requirements; Considering the coupling relationship between multiple tasks, the algorithm self learns to optimize the weight of each task loss, obtains the optimal weight ratio, and constructs a multi task joint network for semantic segmentation and object detection, achieving accurate perception of the autonomous driving environment.
Autonomous vehicle need to perceive the passable area and its main traffic participation targets (pedestrians, vehicles, etc.) in real time during driving. The framework of the Multi Task Joint Driving Environment Visual Perception Algorithm (MadNet) proposed in this article, which integrates temporal information, is as follows:Figure 1As shown: Firstly, using ResNet[24]As a backbone network for efficient temporal feature fusion, in order to increase the receptive field of the network, the convolutions in Stage 4 and Stage 5 of the ResNet structure were replaced with dilated convolutions with a ratio of 1, using two consecutive frames of imagest、t-1 frame of image as input; Secondly, a cascaded feature fusion module is used to balance efficiency and accuracy, resulting in shallow feature maps that contain more detailed informationF2Deep feature maps containing more semantic informationF1Integrating and balancing algorithm accuracy and inference speed; Then, theF1、F2Input temporal feature fusion module to capture non local remote dependencies between image frames, throught-1 frame of image andtKey feature maps of frame imagesKt-1Align feature mapsQtSemantic feature mapVt-1giveVtFusion, matching and aligning temporal features between image frames, resulting in a fused feature mapFtCan provide richer semantic information for subsequent subtask networks; Finally, the semantic segmentation module in the semantic segmentation sub network is used to extract road pixels from the fused feature map. The anchor free heatmap in the object detection sub network is used to detect the center points of traffic participating targets and generate corresponding bounding boxes for them.

be directed againstt-1-frame feature mapXt-1∈ RC×H×W(CFor the number of channels in the feature map,HFor the length of the feature map,WFor the width of the feature map, two 1x1 convolution kernels and their downsampling are used as two branches, with one branch utilizing pyramid pooling to generate the semantic feature mapVt-1∈ Rc×h×w, such asFigure 2As shown, another branch generates key feature mapsKt-1∈ Rc×h×w(c=C/8,h=H/4,w=W/4,c、h、wThe number of channels, length, and width of the feature map after downsampling.

be directed againsttFrame feature mapXt∈ RC×H×WTwo 1x1 convolution kernels are used to downsample and generate semantic feature mapsVt∈Rc×h×wAlign feature maps withQt∈Rc×h×wAmong them, the semantic feature mapVt-1Used to provide rich semantic information and align feature mapsQtUsed for key feature mapsKt-1Integration, realizationtFrame image andt-The temporal alignment between 1 frame of images and their temporal correlationAtdescribed as
| At=S(QtKTt−1/η) | (1) |
In the formula:ηAs a parameter, it is usually taken as√c;S(·) is the Softmax activation function.
Let the fused feature map beFtThe fusion process can be described as
| Ft=Cc(Vt,AtVt−1) | (2) |
In the formula:Cc(·) is the stacking operation in the channel direction between feature maps, where all feature maps have the same length and width.
| Ft=Cc[(n+1∏i=0At−i)Ft−n−1,(n∏i=0At−i)Vt−n,…,AtVt−1,Vt] | (3) |
| At−i=S(Qt−iKTt−i−1/η) | (4) |

As the number of input image frames increases, the computational complexity of the algorithm gradually increases. The impact of different numbers of input image frames on algorithm performance was discussed in detail in the experiment.
In the forward propagation process, a feature fusion module is used to accelerate the algorithm, such asFigure 1 (c)As shown. Specifically, the input image is divided into two branches after being processed by the ResNet network in Stage 3. One branch directly downsamples the feature map propagated to the deep network twice and enters Stage 4, while the other branch generates the feature mapF2Feature maps processed by backbone networksF1At the same time, input the cascaded feature fusion module for processing. Firstly, regardingF1Perform 2x upsampling and use 3x3 dilated convolution to maintain the size of the receptive field; Secondly, regardingF2After 1 × 1 convolution processing and dilated convolutionF1Merge and output.F1Although some detail information was lost in the downsampling before Stage 4, it also achieved faster propagation of semantic feature information, compared to preserving more detail information in the imageF2Parallel input to the cascaded feature fusion module for stacking, resulting in the stacked feature mapXnTo balance the accuracy and speed of the algorithm, the process can be described as
| Xn=R{Cc[γ1(F1),γ2(F2)]} | (5) |
To detect traffic participation elements in each frame of the image, the first step is to usecThe heatmap of the channel predicts the center points of elements such as pedestrians and vehicles in the image, and then regresses the bounding box for each object, where each heatmap contains a detection category. This anchor free detection method has the advantages of fewer hyperparameters, flexibility, and lightweight, and can achieve better detection results compared to algorithms that require anchor box settings. Specifically, when creating supervised data, use the horizontal and vertical coordinates of the top left corner of the object border in the dataset(xlt, ylt)Horizontal and vertical coordinates of the bottom right corner point(xrb, yrb)Obtain the center point of the objectpHorizontal and vertical axis label values(px, py)Due to the lower resolution of the heatmap compared to the data in the dataset, calculate the horizontal and vertical label values of the center point on the corresponding heatmapˉpx=⌊px/m⌋,ˉpy=⌊py/m⌋Generate points on the heatmap using Gaussian kernel formula based on the center point(x, y)The weight ofYThat is
| Y=exp{−[(x−ˉpx)2+(y−ˉpy)2]/2σ2p} | (6) |
In the formula:σpFor adaptive standard deviation.
If two Gaussian regions overlap, select the point with the larger weight. Using logistic regression to calculate the prediction loss of points on the heatmapLhThat is
| Lh=−1N∑x,y,c{(1−ˆY)alg(ˆY)Y=1(1−Y)βˆYalg(1−ˆY)其他 | (7) |
Due to the displacement of the predicted center point during the forward propagation of the image, an additional offset is introduced to correct the discretization error, referred to as the lossL.
| Lo=1N∑p|ˆOˉp−(pm−ˉp)| | (8) |
In the formula:ˆOˉpIt is the center point on the heatmappThe predicted offset; (p/m-p)The offset between the center point of the object and the center point of the heatmap.
| Ls=|ˆs−s| | (9) |
| Lseg=−1N∑x,y,2c[Ylg(ˆY)+(1−Y)lg(1−ˆY)] | (10) |

In the formula:ˆYPredict the semantic values of points on the feature map.
The multi task algorithm constructed can simultaneously achieve semantic segmentation and object detection tasks. Parameter sharing is adopted in the backbone network, so no additional parameter quantity is introduced, keeping the network lightweight and achieving feature sharing. Through end-to-end supervised learning and multi task joint optimization of network parameters, parameter sharing and information complementarity are achieved to enhance the overall performance of the network and improve the running speed of the algorithm.
For the algorithm in this article, the Cityscapes_Sequence dataset is selected[27]Conduct training. Cityscapes_Sequence contains 5000 video clips (totaling 150000 frames of images) and semantic labels corresponding to each frame of image. Among them, 2975 video clips are used for training, 500 video clips are used for validation, and 1525 video clips are used for testing. The high-definition camera at the front of the vehicle was used to capture the video in the dataset, which includes the street views of 18 cities in Europe. Some of the street view data is displayed as followsFigure 5As shown.

Due to the fact that the Cityscapes_Sequence dataset is a semantic segmentation test dataset, it does not provide the corresponding border position data for each object required in the object detection dataset. Therefore, the image data annotation software Labeling is first used to annotate the images with semantic labels in the Cityscapes_Sequence dataset. We have annotated the border positions of common road elements such as pedestrians, vehicles, and traffic signals in the dataset for potential targets encountered during autonomous driving.
In the data augmentation stage before training, in addition to common data augmentation methods such as random rotation, cropping, and translation, mosaic data augmentation is introduced[28]Mixing multiple frames of images into a new image input network can greatly enrich the contextual information of the images and enhance the robustness of the algorithm. in compliance withFigure 6As shown, the mosaic data augmentation method is used to mix 4 training images into one frame and input it into the network.

| L=Lobj2σ21+Lseg2σ22+lg(σ21σ22) | (11) |
| {P=TT+Fr=TT+F′ | (12) |
In the formula:TTo predict the number of positive samples as positive samples;FTo predict the number of negative samples as positive samples;FThe number of samples required to predict positive samples as negative samples.
| ε=(G1∩G2)/(G1∪G2) | (13) |
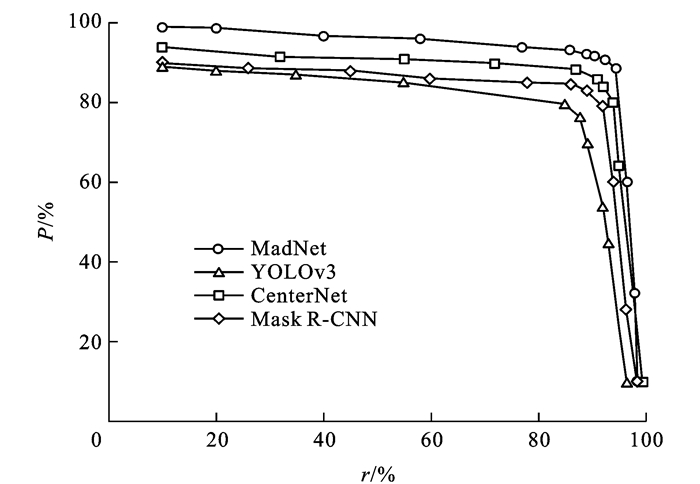
| 算法 | 骨干网络 | 速度/(帧·s-1) | 平均精确率/% | 召回率/% |
| YOLOv3[11] | Darknet53 | 24.0 | 79.2 | 84.9 |
| Mask R-CNN[29] | ResNeXt-101 | 11.4 | 84.2 | 86.2 |
| CornerNet[12] | Hourglass-104 | 4.6 | 86.9 | 86.5 |
| CenterNet[13] | ResNet101 | 6.8 | 87.6 | 87.2 |
| TridentNet[30] | ResNeXt-101-DCN | 0.7 | 91.0 | 88.3 |
| MadNet(Ours) | ResNet50 | 12.6 | 89.8 | 87.8 |
| MadNet(Ours) | ResNet101-DCN | 5.9 | 91.8 | 90.1 |
 DownLoad:
CSV
DownLoad:
CSV
DownLoad:
CSV
DownLoad:
CSV
| 骨干网络 | 速度/(帧·s-1) | 平均交并比/% | 平均精确率/% | 召回率/% |
| ResNet50 | 11.5 | 79.3 | 90.2 | 88.4 |
| ResNet101-DCN | 5.1 | 81.6 | 92.4 | 90.5 |
DownLoad:
CSV
| 插入位置 | 速度/(帧·s-1) | 平均交并比/% | 平均精确率/% | 召回率/% |
| Stage1之后 | 14.0 | 74.8 | 85.7 | 83.4 |
| Stage2之后 | 12.8 | 77.3 | 88.4 | 85.7 |
| Stage3之后 | 11.5 | 79.3 | 90.2 | 88.4 |
| Stage4之后 | 8.4 | 79.6 | 90.5 | 87.6 |
DownLoad:
CSV
| 平均精确率/% | 具体对象的检测精确率/% | ||||
| 自行车 | 卡车 | 行人 | 汽车 | 交通信号灯 | |
| 92.4 | 88.5 | 94.4 | 96.2 | 97.7 | 90.2 |
DownLoad:
CSV

| 输入图像帧数 | 速度/(帧·s-1) | 平均交并比/% | 平均精确率/% | 召回率/% |
| 2 | 11.5 | 79.3 | 90.2 | 88.4 |
| 3 | 8.6 | 79.7 | 91.2 | 88.4 |
| 4 | 4.4 | 79.8 | 91.2 | 88.6 |
DownLoad:
CSV


| [1] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[C]//ICLR. 3rd International Conference on Learning Representations. San Diego: ICLR, 2015: 357-361.
|
| [2] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. doi: 10.1109/TPAMI.2017.2699184
|
| [3] |
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. https://arxiv.org/abs/1706.05587, 2017-08-08/2017-12-05.
|
| [4] |
CHEN L C, ZHU Yu-kun, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Springer. 15th European Conference on Computer Vision. Berlin: Springer, 2018: 833-851.
|
| [5] |
ZHAO Heng-shuang, SHI Jian-ping, QI Xiao-juan, et al. Pyramid scene parsing network[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 6230-6239.
|
| [6] |
ZHAO Heng-shuang, QI Xiao-juan, SHEN Xiao-yong, et al. ICNet for real-time semantic segmentation on high-resolution images[C]//Springer. 15th European Conference on Computer Vision. Berlin: Springer, 2018: 418-434.
|
| [7] |
LIU Zhan-wen, QI Ming-yuan, SHEN Chao, et al. Cascade saccade machine learning network with hierarchical classes for traffic sign detection[J]. Sustainable Cities and Society, 2021, 67: 30914-30928. http://www.sciencedirect.com/science/article/pii/S2210670720309148
|
| [8] |
REN Shao-qing, HE Kai-ming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. doi: 10.1109/TPAMI.2016.2577031
|
| [9] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 779-788.
|
| [10] |
REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 6517-6525.
|
| [11] |
REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. https://arxiv.org/abs/1804.02767, 2018-04-08.
|
| [12] |
LAW H, DENG Jia. CornerNet: detecting objects as paired keypoints[J]. International Journal of Computer Vision, 2020, 128(3): 642-656. doi: 10.1007/s11263-019-01204-1
|
| [13] |
ZHOU Xing-yi, WANG De-quan, KRÄHENBVHL P. Objects as points[EB/OL]. https://arxiv.org/abs/1904.07850v1, 2019-04-16/2019-04-25.
|
| [14] |
ZHAO Yi, QI Ming-yuan, LI Xiao-hui, et al. P-LPN: towards real time pedestrian location perception in complex driving scenes[J]. IEEE Access, 2020, 8: 54730-54740. doi: 10.1109/ACCESS.2020.2981821
|
| [15] |
TEICHMANN M, WEBER M, ZÖLLNER M, et al. MultiNet: Real-time joint semantic reasoning for autonomous driving[C]//IEEE. 2018 IEEE Intelligent Vehicles Symposium. New York: IEEE, 2018: 1013-1020.
|
| [16] |
SISTU G, LEANG I, YOGAMANI S. Real-time joint object detection and semantic segmentation network for automated driving[EB/OL]. https://arxiv.org/abs/1901.03912, 2019-06-12.
|
| [17] |
CHEN Zhao, BADRINARAYANAN V, LEE C Y, et al. GradNorm: gradient normalization for adaptive loss balancing in deep multitask networks[C]//ICML. 35th International Conference on Machine Learning. Stockholm: ICML, 2018: 794-803.
|
| [18] |
KENDALL A, GAL Y, CIPOLLA R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics[C]//IEEE. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 7482-7491.
|
| [19] |
SENER O, KOLTUN V. Multi-task learning as multi-objective optimization[C]//IFIP. 32nd International Conference on Neural Information Processing Systems. Rome: IFIP, 2017: 525-526.
|
| [20] |
ZHAO Xiang-mo, QI Ming-yuan, LIU Zhan-wen, et al. End-to-end autonomous driving decision model joined by attention mechanism and spatiotemporal features[J]. IET Intelligent Transport Systems, 2021, 8: 1119-1130. http://www.researchgate.net/publication/352733796_End-to-end_autonomous_driving_decision_model_joined_by_attention_mechanism_and_spatiotemporal_features
|
| [21] |
LI Yu-le, SHI Jian-ping, LIN Da-hua. Low-latency video semantic segmentation[C]//IEEE. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 5997-6005.
|
| [22] |
FENG Jun-yi, LI Song-yuan, LI Xi, et al. TapLab: a fast framework for semantic video segmentation tapping into compressed-domain knowledge[J]. IEEE Transactions on Software Engineering, 2020, https://ieeexplore.ieee.org/document/9207876.
|
| [23] |
WU Jun-rong, WEN Zong-zheng, ZHAO San-yuan, et al. Video semantic segmentation via feature propagation with holistic attention[J]. Pattern Recognition, 2020, 104, DOI: 10.1016/j.patcog.2020.107268.
|
| [24] |
HE Kai-ming, ZHANG Xiang-yu, REN Shao-qing, et al. Identity mappings in deep residual networks[C]//ACM. 14th European Conference on 21st ACM Conference on Computer Vision. Berlin: Springer, 2016: 630-645.
|
| [25] |
HU Ping, HEILBRON F C, WANG O, et al. Temporally distributed networks for fast video semantic segmentation[C]//IEEE. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 8815-8824.
|
| [26] |
ZHU Zhen, XU Meng-du, BAI Song, et al. Asymmetric non-local neural networks for semantic segmentation[C]//IEEE. 2019 International Conference on Computer Vision. New York: IEEE, 2019: 593-602.
|
| [27] |
CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]//IEEE. 29th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 3213-3223.
|
| [28] |
YUN S D, HAN D Y, OH S J, et al. CutMix: regularization strategy to train strong classifiers with localizable features[C]//IEEE. 2019 International Conference on Computer Vision. New York: IEEE, 2019: 6022-6031.
|
| [29] |
HE Kai-ming, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 386-397. doi: 10.1109/TPAMI.2018.2844175
|
| [30] |
LI Yang-hao, CHEN Yun-tao, WANG Nai-yan, et al. Scale-aware trident networks for object detection[C]//IEEE. 2019 International Conference on Computer Vision. New York: IEEE, 2019: 6053-6062.
|
| [31] |
ZHU Xi-zhou, XIONG Yu-wen, DAI Ji-feng, et al. Deep feature flow for video recognition[C]//IEEE. 30th IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 4141-4150.
|
| [1] | DING Jian-ming, ZHOU Jing-yao, JIANG Hai-fan. In-vehicle image technology for identifying faults of pantograph[J]. Journal of Traffic and Transportation Engineering, 2023, 23(3): 173-187. doi: 10.19818/j.cnki.1671-1637.2023.03.013 |
| [2] | PENG Jia-li, SHANGGUAN Wei, CHAI Lin-guo, QIU Wei-zhi. Car-following model and optimization strategy for connected and automated vehicles under mixed traffic environment[J]. Journal of Traffic and Transportation Engineering, 2023, 23(3): 232-247. doi: 10.19818/j.cnki.1671-1637.2023.03.018 |
| [3] | ZHANG Wei-guang, ZHONG Jing-tao, HUYAN Ju, MA Tao, ZHU Jun-qing, HE Liang. Extraction and quantification of pavement alligator crack morphology based on VGG16-UNet semantic segmentation model[J]. Journal of Traffic and Transportation Engineering, 2023, 23(2): 166-182. doi: 10.19818/j.cnki.1671-1637.2023.02.012 |
| [4] | GAO Yang, CAO Wang-xin, XIA Hong-yao, ZHAO Yi-hui. Driverless vehicle positioning algorithm based on simultaneous positioning and mapping in low-visibility environment[J]. Journal of Traffic and Transportation Engineering, 2022, 22(3): 251-262. doi: 10.19818/j.cnki.1671-1637.2022.03.020 |
| [5] | YANG Biao, YAN Guo-cheng, LIU Zhan-wen, LIU Xiao-feng. Perception of moving objects in traffic scenes based on heterogeneous graph learning[J]. Journal of Traffic and Transportation Engineering, 2022, 22(3): 238-250. doi: 10.19818/j.cnki.1671-1637.2022.03.019 |
| [6] | CHEN Ting, YAO Da-chun, GAO Tao, QIU Hui-hui, GUO Chang-xin, LIU Zhan-wen, LI Yong-hui, BIAN Hao-yi. A fused network based on PReNet and YOLOv4 for traffic object detection in rainy environment[J]. Journal of Traffic and Transportation Engineering, 2022, 22(3): 225-237. doi: 10.19818/j.cnki.1671-1637.2022.03.018 |
| [7] | WANG Zheng-hong, YANG Chuan. Improved SSD model in extraction application of expressway toll station locations from GaoFen 2 remote sensing image[J]. Journal of Traffic and Transportation Engineering, 2021, 21(2): 278-286. doi: 10.19818/j.cnki.1671-1637.2021.02.024 |
| [8] | LIU Lei, ZHANG Yong, ZHANG Ming-yang, WANG Yong-ming, CHEN Jing. Analysis and optimization of ship trajectory dissimilarity models based on multi-feature fusion[J]. Journal of Traffic and Transportation Engineering, 2021, 21(5): 199-213. doi: 10.19818/j.cnki.1671-1637.2021.05.017 |
| [9] | YANG Wei, HUANG Li-hong, ZHAO Xiang-mo, WANG Xiao. Puddle area segmentation of asphalt pavements based on FRRN attention and supervision[J]. Journal of Traffic and Transportation Engineering, 2021, 21(5): 309-322. doi: 10.19818/j.cnki.1671-1637.2021.05.026 |
| [10] | LI Xun, LIU Yao, LI Peng-fei, ZHANG Lei, ZHAO Zheng-fan. Vehicle multi-target detection method based on YOLO v2 algorithm under darknet framework[J]. Journal of Traffic and Transportation Engineering, 2018, 18(6): 142-158. doi: 10.19818/j.cnki.1671-1637.2018.06.015 |
| [11] | LIANG Min-jian, CUI Xiao-yu, SONG Qing-song, ZHAO Xiang-mo. Traffic sign recognition method based on HOG-Gabor feature fusion and Softmax classifier[J]. Journal of Traffic and Transportation Engineering, 2017, 17(3): 151-158. |
| [12] | LIU Xing-long, CHU Xiu-min, MA Feng, LEI Jin-yu. Discriminating method of abnormal dynamic information in AIS messages[J]. Journal of Traffic and Transportation Engineering, 2016, 16(5): 142-150. doi: 10.19818/j.cnki.1671-1637.2016.05.016 |
| [13] | ZHANG Shao-yang, GE Li-juan, AN Yi-sheng, CAO Jin-shan. Research status and development of transportation data standards[J]. Journal of Traffic and Transportation Engineering, 2014, 14(2): 112-126. |
| [14] | LIU Qin, XU Jian-min. Coordinated control model of regional traffic signals[J]. Journal of Traffic and Transportation Engineering, 2012, 12(3): 108-112. doi: 10.19818/j.cnki.1671-1637.2012.03.016 |
| [15] | YU Bin, WU Shan-hua, WANG Ming-hua, ZHAO Zhi-hong. K-nearest neighbor model of short-term traffic flow forecast[J]. Journal of Traffic and Transportation Engineering, 2012, 12(2): 105-111. doi: 10.19818/j.cnki.1671-1637.2012.02.015 |
| [16] | HU Hua, GAO Yun-feng, YANG Xiao-guang. Probabilistic traffic forecast method based on comprehensive transport information platform[J]. Journal of Traffic and Transportation Engineering, 2009, 9(3): 122-126. doi: 10.19818/j.cnki.1671-1637.2009.03.024 |
| [17] | ZHANG Da-qi, QU Shi-ru, SHI Shuang. Edge detection algorithm of moving vehicle based on sequential image motion segmentation[J]. Journal of Traffic and Transportation Engineering, 2009, 9(3): 117-121. doi: 10.19818/j.cnki.1671-1637.2009.03.023 |
| [18] | HE Si-hua, YANG Shao-qing, SHI Ai-guo, LI Tian-wei. Ship target detection algorithm on sea surface based on block chaos feature of image sequence[J]. Journal of Traffic and Transportation Engineering, 2009, 9(1): 73-76. doi: 10.19818/j.cnki.1671-1637.2009.01.015 |
| [19] | ZHANG Ning, HE Tie-jun, GAO Chao-hui, HUANG Wei. Detection method of traffic signs in road scenes[J]. Journal of Traffic and Transportation Engineering, 2008, 8(6): 104-109. |
| [20] | SHI Xin. Information organizing and transforming of value-added information system of port and shipping EDI[J]. Journal of Traffic and Transportation Engineering, 2005, 5(2): 85-88. |

Figures(9) / Tables(6)
Copyright《Journal of Traffic and Transportation Engineering》编辑部陕ICP备05001904号-1
Address :Editorial Department of Journal of Traffic and Transportation Engineering, Chang 'an University, Middle Section of South Second Ring Road, Xi 'an, Shaanxi(710064) Tel:029-82334388 Email:jygc@chd.edu.cn
All visit:1713577Today's visit:237
Supported by:
Beijing Renhe Information Technology Co. Ltd

CAO Jian-ming, WU Tao, CHENG Qian, QI Dong-hui, BIAN Yao-zhang. Atomization characteristics comparison between diesel and LPG/diesel dual fuel[J]. Journal of Traffic and Transportation Engineering, 2003, 3(2): 40-44.

| 算法 | 骨干网络 | 速度/(帧·s-1) | 平均精确率/% | 召回率/% |
| YOLOv3[11] | Darknet53 | 24.0 | 79.2 | 84.9 |
| Mask R-CNN[29] | ResNeXt-101 | 11.4 | 84.2 | 86.2 |
| CornerNet[12] | Hourglass-104 | 4.6 | 86.9 | 86.5 |
| CenterNet[13] | ResNet101 | 6.8 | 87.6 | 87.2 |
| TridentNet[30] | ResNeXt-101-DCN | 0.7 | 91.0 | 88.3 |
| MadNet(Ours) | ResNet50 | 12.6 | 89.8 | 87.8 |
| MadNet(Ours) | ResNet101-DCN | 5.9 | 91.8 | 90.1 |
DownLoad:
CSV
DownLoad:
CSV
| 骨干网络 | 速度/(帧·s-1) | 平均交并比/% | 平均精确率/% | 召回率/% |
| ResNet50 | 11.5 | 79.3 | 90.2 | 88.4 |
| ResNet101-DCN | 5.1 | 81.6 | 92.4 | 90.5 |
DownLoad:
CSV
| 插入位置 | 速度/(帧·s-1) | 平均交并比/% | 平均精确率/% | 召回率/% |
| Stage1之后 | 14.0 | 74.8 | 85.7 | 83.4 |
| Stage2之后 | 12.8 | 77.3 | 88.4 | 85.7 |
| Stage3之后 | 11.5 | 79.3 | 90.2 | 88.4 |
| Stage4之后 | 8.4 | 79.6 | 90.5 | 87.6 |
DownLoad:
CSV
| 平均精确率/% | 具体对象的检测精确率/% | ||||
| 自行车 | 卡车 | 行人 | 汽车 | 交通信号灯 | |
| 92.4 | 88.5 | 94.4 | 96.2 | 97.7 | 90.2 |
DownLoad:
CSV
| 输入图像帧数 | 速度/(帧·s-1) | 平均交并比/% | 平均精确率/% | 召回率/% |
| 2 | 11.5 | 79.3 | 90.2 | 88.4 |
| 3 | 8.6 | 79.7 | 91.2 | 88.4 |
| 4 | 4.4 | 79.8 | 91.2 | 88.6 |
DownLoad:
CSV
| 算法 | 骨干网络 | 速度/(帧·s-1) | 平均精确率/% | 召回率/% |
| YOLOv3[11] | Darknet53 | 24.0 | 79.2 | 84.9 |
| Mask R-CNN[29] | ResNeXt-101 | 11.4 | 84.2 | 86.2 |
| CornerNet[12] | Hourglass-104 | 4.6 | 86.9 | 86.5 |
| CenterNet[13] | ResNet101 | 6.8 | 87.6 | 87.2 |
| TridentNet[30] | ResNeXt-101-DCN | 0.7 | 91.0 | 88.3 |
| MadNet(Ours) | ResNet50 | 12.6 | 89.8 | 87.8 |
| MadNet(Ours) | ResNet101-DCN | 5.9 | 91.8 | 90.1 |
| 骨干网络 | 速度/(帧·s-1) | 平均交并比/% | 平均精确率/% | 召回率/% |
| ResNet50 | 11.5 | 79.3 | 90.2 | 88.4 |
| ResNet101-DCN | 5.1 | 81.6 | 92.4 | 90.5 |
| 插入位置 | 速度/(帧·s-1) | 平均交并比/% | 平均精确率/% | 召回率/% |
| Stage1之后 | 14.0 | 74.8 | 85.7 | 83.4 |
| Stage2之后 | 12.8 | 77.3 | 88.4 | 85.7 |
| Stage3之后 | 11.5 | 79.3 | 90.2 | 88.4 |
| Stage4之后 | 8.4 | 79.6 | 90.5 | 87.6 |
| 平均精确率/% | 具体对象的检测精确率/% | ||||
| 自行车 | 卡车 | 行人 | 汽车 | 交通信号灯 | |
| 92.4 | 88.5 | 94.4 | 96.2 | 97.7 | 90.2 |
| 输入图像帧数 | 速度/(帧·s-1) | 平均交并比/% | 平均精确率/% | 召回率/% |
| 2 | 11.5 | 79.3 | 90.2 | 88.4 |
| 3 | 8.6 | 79.7 | 91.2 | 88.4 |
| 4 | 4.4 | 79.8 | 91.2 | 88.6 |

 DownLoad:
DownLoad:

 DownLoad:
DownLoad: